Display highlighted PDFs in Streamlit
Posted on
and make LLMs more trust-worthy.
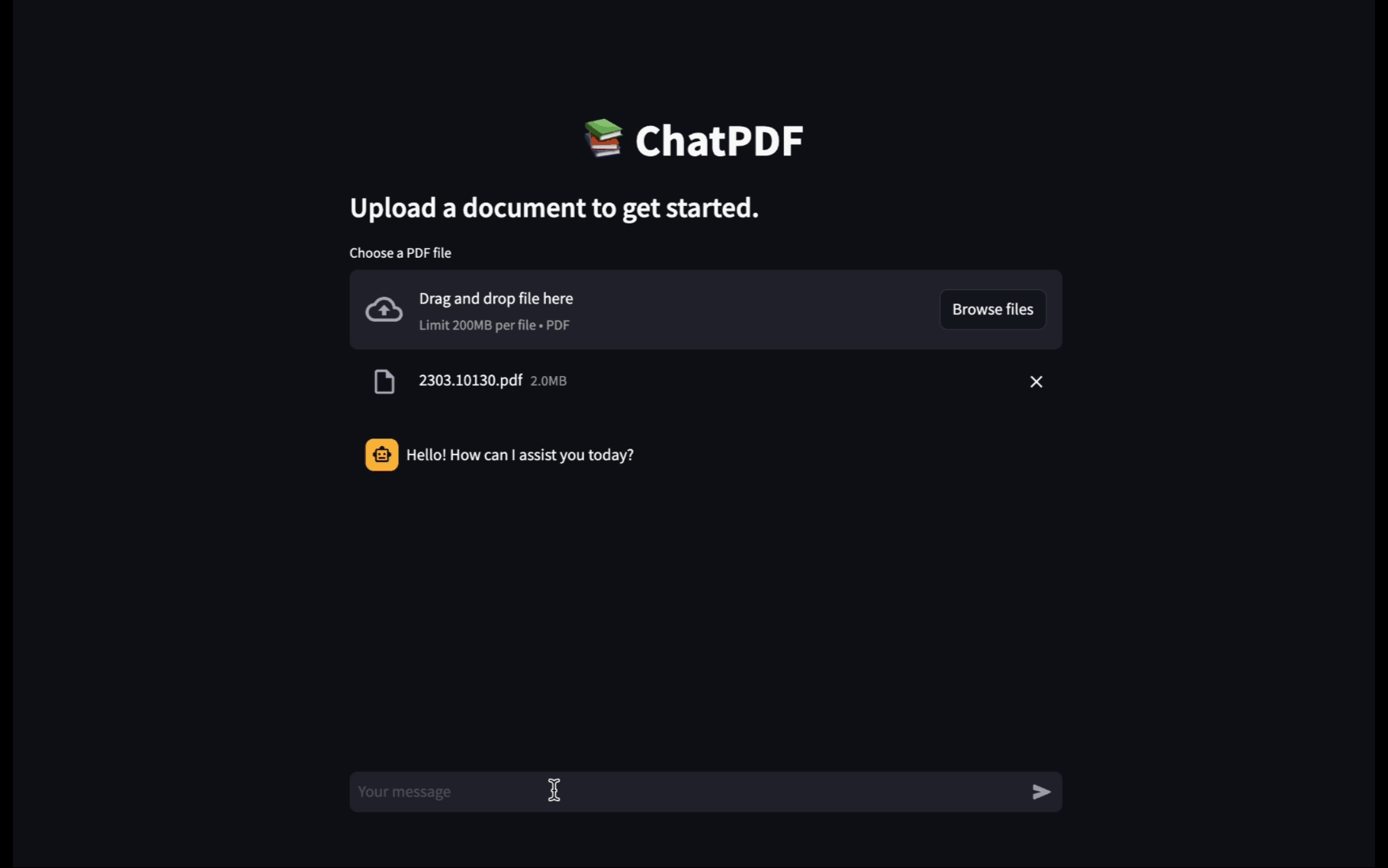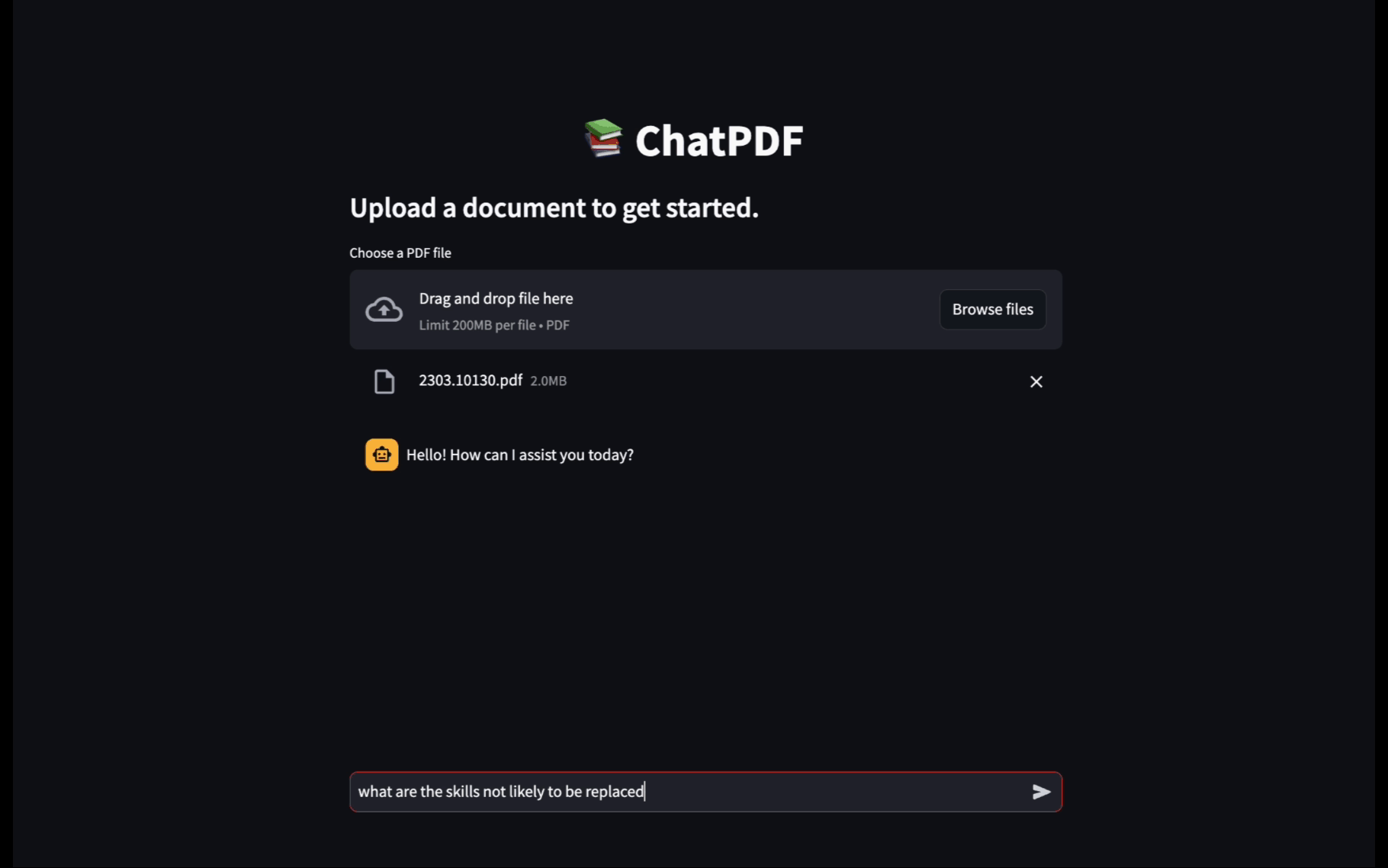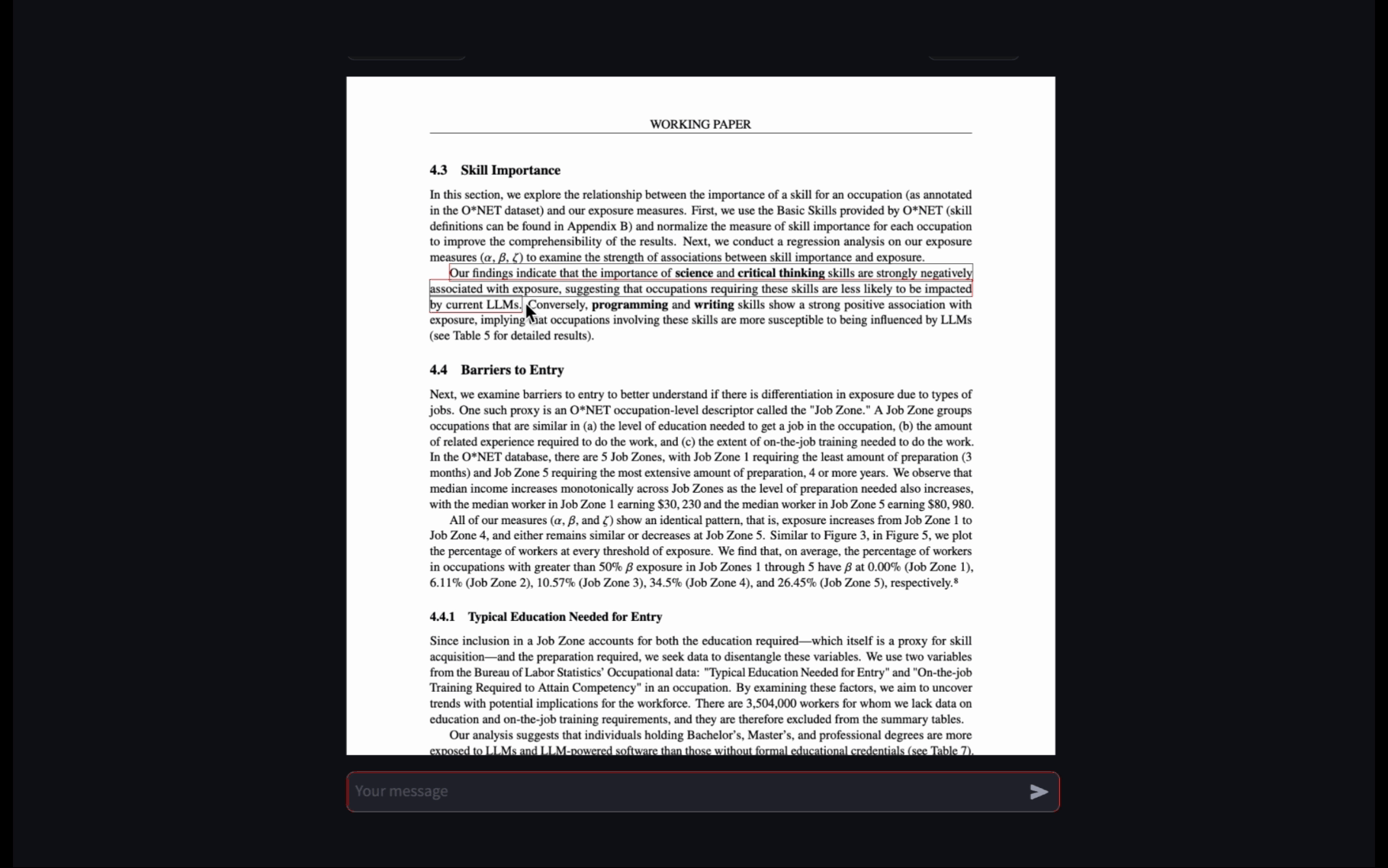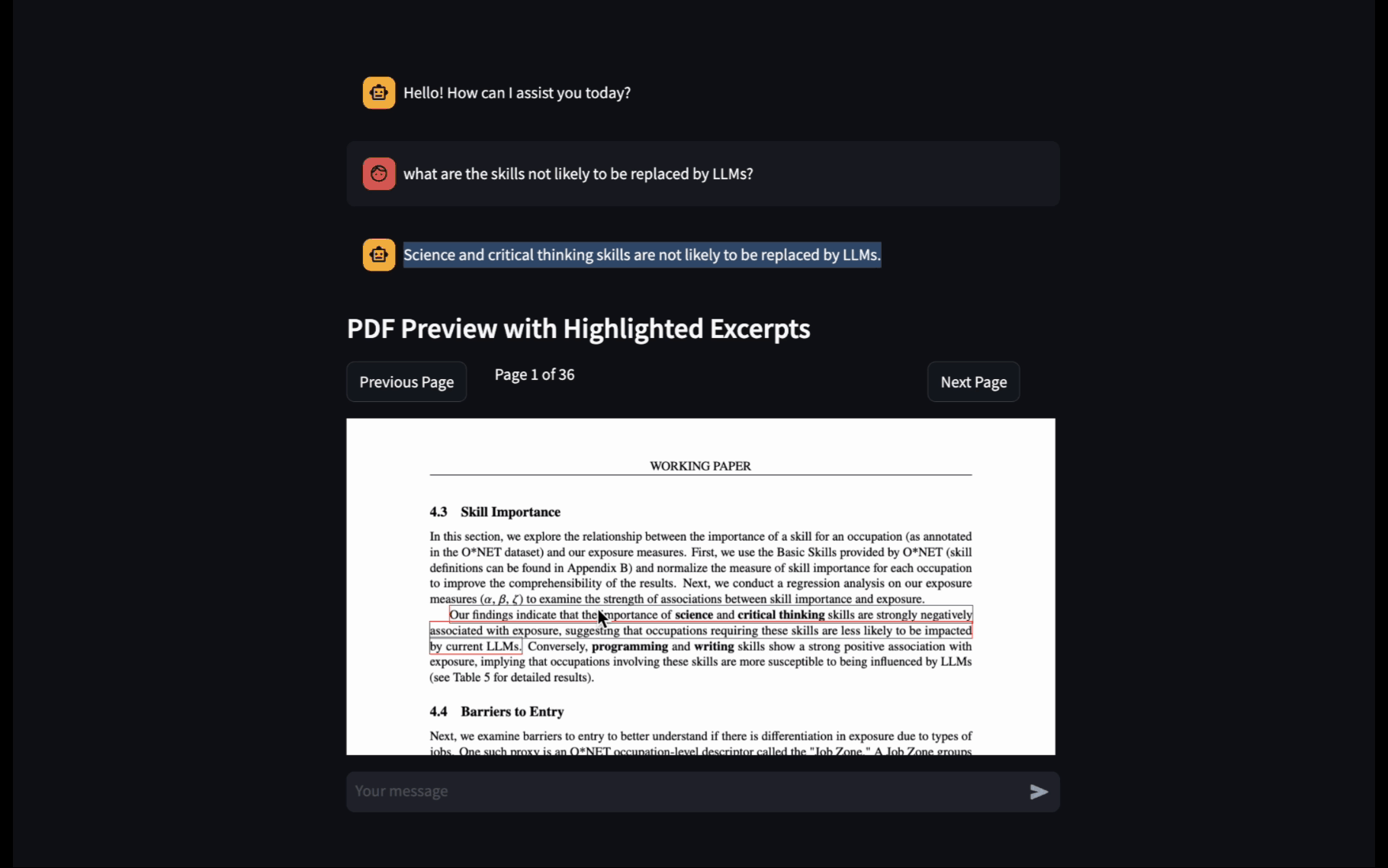
Hallucination which happens when an AI model makes stuff up is a heavily discussed topic. I think this is the #1 roadblock for companies to adopt LLMs in production since people can’t 100% trust the model output.

Over the last years working with LLMs projects, I have realized that users greatly value the ability to retrieve the exact excerpts, sentences, or paragraphs from documents that the language models use to generate their answers.
Enhancing this feature by highlighting and displaying the relevant information directly in the user interface can significantly improve user experience. The advantage is to allow the system to provide users the transparency, enable human verifications and gradually build trust in the AI system. Asking the LLMs to return the sources is also a good way to reduce its hallucinations.
Since I have been looking for a way to render the PDF with highlighted relevant text directly in Streamlit, I am really happy to find this streamlit-pdf-review package that allows you to manipulate and display PDF in the app. If you want a native PDF viewing experience within Streamlit, this article is for you.
Prompt the LLM to Return Exact Sources
To highlight the relevant text, we need the AI system to not only provide an answer but also display the exact excerpts from the document where the answer is based. To achieve this, the first step is to ask the LLM to return the exact sources from the document.
While you could use a RAG (Retrieval-Augmented Generation) architecture to return relevant chunks of text, this approach may not be that intuitive and user-friendly, as users would still need to read through the entire chunk of text. Instead, it maybe more effective to have the model return specific sources. Here’s how you can prompt the model to return these sources:
custom_template = """
Use the following pieces of context to answer the user question. If you
don’t know the answer, just say that you don’t know, don’t try to make up
an answer.
{context}
Question: {question}
Please provide your answer in the following JSON format:
{{
"answer": "Your detailed answer here",
"sources": "Direct sentences or paragraphs from the context that
support your answers. ONLY RELEVANT TEXT DIRECTLY FROM THE
DOCUMENTS. DO NOT ADD ANYTHING EXTRA. DO NOT INVENT ANYTHING."
}}
The JSON must be a valid json format and can be read with json.loads() in
Python. Answer:
"""
CUSTOM_PROMPT = PromptTemplate(
template=custom_template, input_variables=[“context”, “question”]
)
and use that for the QA part:
qa = RetrievalQA.from_chain_type(
llm,
chain_type=“stuff”,
retriever=retriever,
return_source_documents=True,
chain_type_kwargs={“prompt”: CUSTOM_PROMPT},
)
Highlight and display relevant text in the PDF
Once we have the exact excerpts from the LLM, the next step is to find and highlight these excerpts in the PDF and display the highligted PDF in Streamlit.
The streamlit plugin streamlit-pdf-viewer provides an easy interface to display PDFs with annotations overlaid on top. The format of the annotations parameter in streamlit-pdf-viewer is derived from Grobid’s coordinate formats, which are a list of “bounding boxes”. The annotations are expressed as a dictionary of six elements: page (the page number where the annotation should be drawn), x and y (coordinates of the top-left corner), width and height (dimensions of the bounding box), and color (the outline color):
annotations = {
“page”: 1,
“x”: 220,
“y”: 155,
“height”: 22,
“width”: 65,
“color”: “red”
}
So to be able to highlight the relevant text, you will need to:
- Determine the page where the excerpt is on.
- Produce the annotations: find the correct coordinates of the excerpt on its respective page and highlight.
- Display the highlighted PDF with streamlit-pdf-viewer
Step 1: Determine the page where the excerpt is on
To effectively highlight text in a PDF, we need to determine which pages contain the relevant excerpts. We can use a library like PyMuPDF (fitz) to search for the text and the page number. The find_pages_with_excerpts function does exactly this by searching for specified text excerpts within the document and returning the pages on which they are found:
import fitz
doc = fitz.open(stream=io.BytesIO(file), filetype=“pdf”)
def find_pages_with_excerpts(doc, excerpts):
pages_with_excerpts = []
for page_num in range(len(doc)):
page = doc.load_page(page_num)
for excerpt in excerpts:
text_instances = page.search_for(excerpt)
if text_instances:
pages_with_excerpts.append(page_num+1)
break
return (
pages_with_excerpts if pages_with_excerpts else [1]
)
pages_with_excerpts = find_pages_with_excerpts(doc, sources)
Step 2: Produce the annotations
Once we have identified the pages with the excerpts, we need to produce the annotations. The following function will search for the text excerpts in each page of the PDF, create bounding boxes for the text instances found, and store them as annotations:
def get_highlight_info(doc, excerpts):
annotations = []
for page_num in range(len(doc)):
page = doc[page_num]
for excerpt in excerpts:
text_instances = page.search_for(excerpt)
if text_instances:
for inst in text_instances:
annotations.append(
{
“page”: page_num + 1,
“x”: inst.x0,
“y”: inst.y0,
“width”: inst.x1 - inst.x0,
“height”: inst.y1 - inst.y0,
“color”: “red”,
}
)
return annotations
annotations = get_highlight_info(doc, st.session_state.sources)
Step 3: Displaying the highlighted PDF with streamlit-pdf-viewer
The final step is to display the PDF with the highlighted excerpts using streamlit-pdf-viewer. This plugin allows us to pass the PDF content, annotations, and other parameters to create an interactive viewing experience:
from streamlit_pdf_viewer import pdf_viewer
# Find the first page with excerpts
if annotations:
first_page_with_excerpts = min(ann[“page”] for ann in annotations)
else:
first_page_with_excerpts = st.session_state.current_page + 1
pdf_viewer(
file,
width=700,
height=800,
annotations=annotations,
pages_to_render=[first_page_with_excerpts],
)
And voila! that’s all there is to it :) The complete source code for the demo app below can be found on my GitHub:
Happy learning 📚😊!