GenAI’s products: Move fast and fail
Posted on

In Autumn 2022, I was working on a cool project. Yes, you guessed it — finetuning a pre-trained LLM (Bert) using company-specific data.
However, soon enough, ChatGPT was released and has taken the world by storm. And what is the point of me trying to finetune a LLM when there is one out there that is super powerful?
I have been a huge fan of Bert so when ChatGPT was released, I got caught up in that buzz too. I mean, who wouldn’t? The promise of AI was like a shiny new toy, and I was eager to play it. In this article, I would like to share my journey of a (NLP) data scientist who was craving to make impact with GenAI.
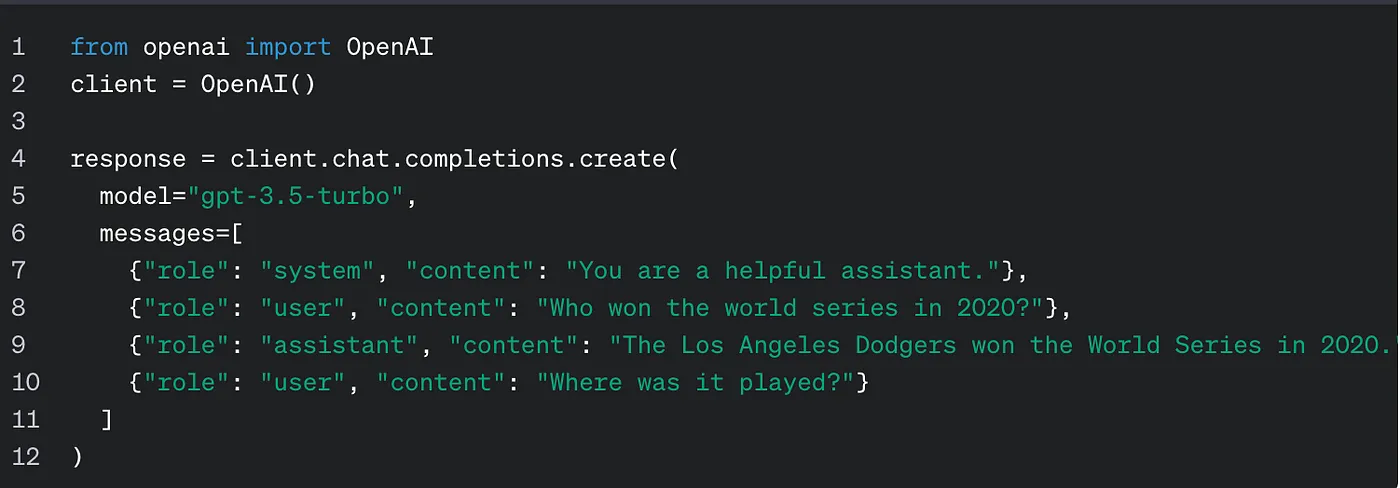
I started being involved in GenAI projects in early 2023 when the big boss wanted to do something with this new technology. I realized how lucky I was, not every executive is open to exploring the frontiers of GenAI. Soon enough, we are onboarded on the list of users on AzureOpenAI, and the party officially starts 💃.
Building a cool demo is easy
There are 1.4 billion ways to use the OpenAI models, but I need to make things work along the company tech stack and security policy.
For one project, I must develop front-end solution for an AI application. In a week, there were 1 billion things I needed to learn. I had to deploy a model endpoint on Azure, which I can use for my app. Front-end-wise, I learnt to build the app with Streamlit. That is relatively easy. In just a day, I have an app up and running locally.
Now that the app is built, it is time to show it off to the world.
This, to be fair, was not easy. I needed to make sure that the application follows the company’s security policy. We don’t have a standard workflow to deploy applications, so I have to figure out lots of things myself. I needed to learn how to use a yml file for Azure pipeline and deploy local apps through Azure’s web app service. My days were also filled with figuring out proper access management, storing data on Azure blob storage, or managing user data in Hive storage. It was a steep, sometimes overwhelming, learning curve.
The combination of Langchain, Streamlit, Azure OpenAI and Azure app services works like a charm. In just a week, I had a demo to share with people. It looks so cool, well at least at first glance. Appreciation comes my way, and I feel like a tech wizard who is on my way to create impact. Yes, Impact. That is what I was craving for.
However, that feeling does not last long. In fact, very soon, I realized that just calling the model and prompting are not enough. That is just the tip of the iceberg.
Prototypes are prototypes. They are open to massive improvements.
Soon, the problems arrive
The first problem is called Token Limit.

If you work with LLM models, sooner or later, you get yourself in trouble because the model returns an error, and it says that you have exceeded the model’s maximum context length! You can argue, no problem, GPT-4 offers a context length of 128k, and voila, problem solved.
Well, not really.
The way language models like GPT maintain context over long conversations is through “contextual condensation”. This means that when the model gets a new input that exceeds its context window size, it must discard the oldest input to make space for the new one. During this process, it keeps track of the previous context through its internal state, which is a sort of compressed summary of the discarded information.

As conversations grow longer, the quality of the “contextual condensation” can degrade, leading to what is referred to as context drift, where the model may start to lose track of key details or the overall thread of the conversation.
So, increasing context length would not address the issue. And at some points, you will reach the token limit again.
I needed to learn how to solve this problem. It is a priority because otherwise, people can’t go on. I have written another article about dealing with the model’s context length; feel free to have a look here.
Hallucinations vs factuality
Then, there were hallucinations versus factuality. ChatGPT is amazing, but it is also not that amazing.
People say that you have to write a good prompt, and that is very true. You can see massive improvements in the output with the good prompts. At the same time, even with the best possible prompt you can think of, it will still give you wrong answers. It unfortunately hallucinates the most when you want it to hallucinate the least. When you ask difficult questions, it can be confidently wrong.
You start questioning — does the model understand at all? If it does, it would not make these mistakes.
Perhaps it is time to believe that it is not that amazing. At least not all the time.

And because chatGPT is a probability model in nature — which I have explain thoroughly in another article, that predicts the probability of which token is coming next, a little bit of error for each token prediction can add up and by the time the model has created many tokens down the path, it could produce nonsense.
It is like sitting in a rocket flying to the moon. Being off by a tiny amount does not seem to be a big deal at first but over the course of a long journey, you will end up missing the Moon and being lost in space.
Fortunately, parameters such as temperature and top_p sampling are powerful tools for controlling the behavior of Chat-GPT family models, which can be used when making API calls. By adjusting these parameters, you can achieve different levels of randomness and control. The thing is that experimenting with setting up these hyper-parameters would take time too.
Reproducibility
Good luck with this.
For one project, I needed to analyse the speeches of central banks. The output will be used for a predictive model. For this project, obtaining robust and re-producible output is crucial.
However, the output from ChatGPT is not always reproducible. Chat Completions are non-deterministic by default, which means model outputs may differ from request to request.
ChatGPT is built upon transformer architecture, which contains a linear layer on top of transformer layer. The linear layer transforms the output of the Transformer layer into a set of scores to predict the next word/token in a sentence. Each possible next token gets a score. These scores are then passed through a SoftMax function to get probabilities. The word with the highest probability is selected as the prediction. I have another article that explains how ChatGPT works, feel free to have a look.

And because there are many possible words that could come next, there is an element of randomness in the way a model can respond.
I could not really get a peace of mind for this project because every time I call the model, I do not know what exactly I would get in return. That scares me out.
Fortunately, you can minimize this risk by adjusting some model settings, such as the temperature. Recently, OpenAI has implemented seed variables for reproducibility. Developers can now specify the seed parameter in the Chat Completion request for consistent completions. Phews!
It is a process. We need to prototype, collect feedback, evaluate, and iterate
As my AI application was deployed and tested, feedback was coming my way. For example, some users say that the output of chunking strategies does not seem to work well. The model tends to skip important details. Another user commented that there were too many fluctuations in the model’s output.
GenAI is a new thing, I am also just learning. From these feedback, I had some ideas to improve the quality of the outputs.
For instance, few-shot learning is an useful technique too. It enables pre-trained AI model to learn from a small number of examples and apply that learning to new, unseen data. In my case, that was extremely useful when coping with complex topics in speeches from central banks.
Or advanced prompt engineering techniques like Chain-of-Thought prompting does not seem to get the spotlight it deserves.
Nevertheless, as I was running multiple projects at the same time — Yes, it is me to be blamed, I feel like as soon as one feature was added, a new feature request comes in, either from the same or a different project. There was not enough time to tune what I already developed. It is like a loop. Every time I am done adding a new feature, there is something else.
First, token limit issue has to be solved.
Next on the list, it needs to be able to read more file formats.
Let’s also create a real-time feedback functionality to track the performance of the model.
What to do with evaluation?
Or “Can you return output in a nicely formatted PDF?”
People can keep going on and asking for a shiny new feature like “can you make it like chat.openai.com”?
It feel like cooking a huge meal but not getting the time to sit down and eat it. So that is not a good idea.
It is like starting your day with a shot of tequila at 8:00 am. — Bill Inmon
At the same time, I had to explain to the users why the current outputs were not that great. It is not always an easy conversation. People want what they want. If you can’t deliver, it does not matter what the problems are.
In other words, I had been building many first versions, but could not tune them and none of them would have made the product stand out. I felt like I was losing my credibility.
GenAI is User Centric
AI literacy is less about how to finetune a pre-trained AI model or build a new AI model from scratch, but more about how to use AI appropriately.
It is because GenAI is user-centric.
Let me give you an example. I built an MVP app that allows users to upload documents and have a chat interface. One of the users came to me saying the app does not receive the document anymore.
Turns out that the user was asking: “Can you see the attached document”?
To which the model responded: “As an AI language model, I can not see or perceive documents….”

Obviously, the way I set it up was that a user could upload a document, which I then extracted the text from the uploaded document and fetched it to chatGPT. That said, the model can only “see” the text, it could not “see” the attached document in a traditional sense, like us human see it on a screen. Given the way I set up the tool, a wrong question was asked.
If you ask for a summary or to answer a question, it works perfectly fine.
That is why I think the GenAI project should also focus on educating people on how to use AI, from understanding at a high level how GenAI works to different prompting strategies.
Evaluation of GenAI output
Evaluating the output of GenAI models is as crucial as it is challenging.
Back in the day before the GenAI time, you simply split your data into training/test/validation sets — train your model on the training set and evaluate performance on the validation and test set. In supervised learning, we use R-squared, Precision, recall, or F-sore to evaluate performance. How is a Large Language Model evaluated? What is the ground truth when it comes to generating new texts?
Without evaluating the output of a model, how can we be so sure that it is doing what it is supposed to do? Human judgment plays a crucial role, yes, but if every AI’s output requires a human’s evaluation, we have merely traded one manual task for another, failing to harness the time-saving objective of using AI.
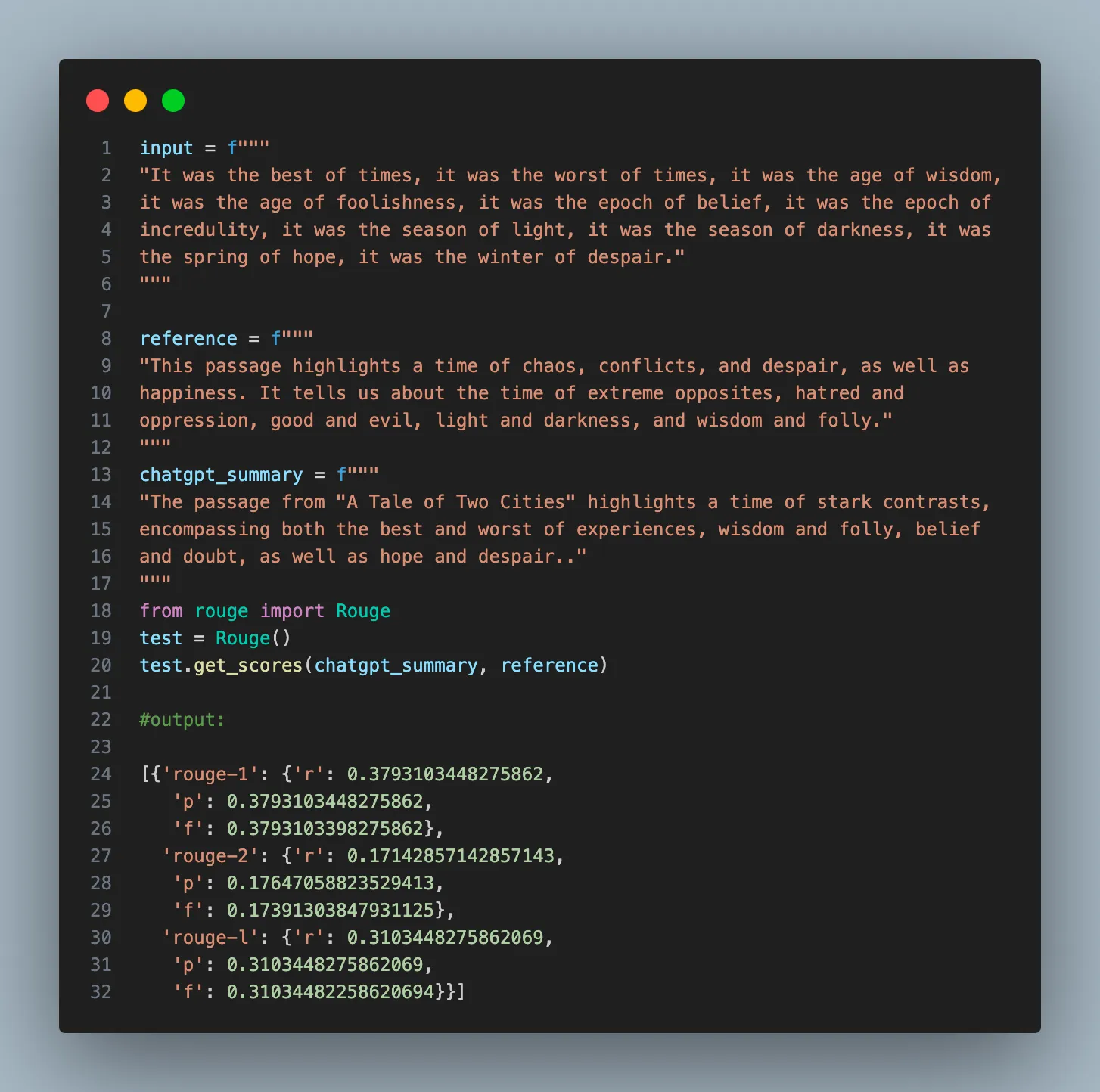
At the moment of writing this, I am experimenting with different evaluation strategies. Take text summary, for example, one of the most common metrics is using ROUGE score, see Holistic Evaluation of Language Models. In a future post, I will write about different techniques for evaluating LLM’s output.
Manage the expectation — GenAI is not tailored to a specific problem
I remembered watching a talk by Andrew Ng, where he mentioned that fast forward to today, the AI landscape has dramatically changed.
In the old days, a data team needed to build and deploy a machine-learning model before building and deploying AI applications, which can take months, even a year.
Thanks to the ready-to-use large language models like ChatGPT or Bard, you can deploy applications in a fraction of the time using a prompt-based AI workflow, which could look like this:
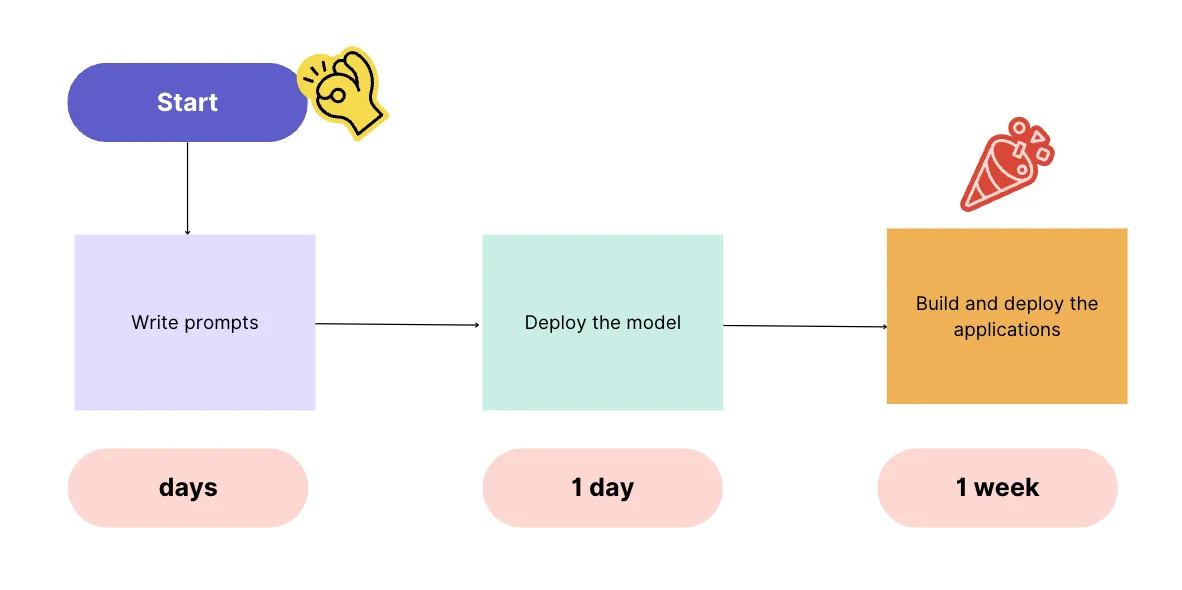
With all respect, I wish that was true**.** If your goal is just to showcase cool demos and the potential of using AI to get more funding for your project, sure, go for it. But for a real and impactful product? I highly doubt if it is that easy. GenAI models are generic and not tailored to specific business problems.
Back in the days, machine learning models have always been built to solve a specific problem. You can build recommendation systems that recommend which products to buy on Amazon or which movies to watch on Netflix. Since Bert was first developed in 2018, language models were mainly used for specific tasks, and they performed well at these narrow tasks. For instance, you always need to fine-tune a pre-trained generic Bert model for a specific task, such as POS tagging, question-answering, or sentiment analysis. For example, if I fine-tune a BERT model specific for understanding sustainability topics, I would not expect it to be an expert in understanding financial or legal texts.
Given the hype in the AI industry, expectation management is the key.
Lessons for business
One thing I can say for sure, Calling OpenAI’s model with a standard prompt like “summarise the document” is not enough to build a final product.
Pre-trained GenAI models like ChatGPT are generic models who can do a lot of things. However, they are not tailored to a specific business problem. If you want a final product that transforms your business, GenAI must be treated as a real project. It must first start with understanding the pains and setting clear goals for what you expect that product to bring and the resources you are willing to invest.
A GenAI project needs the right people to be successful. It needs not only a visionary leader who sees the potential of GenAI, but also a team that combines diverse skills. It needs the business users who know their pains and what they want. It needs data scientists that understand how the model works, Machine Learning engineers/Cloud Platform Engineers and the IT troubleshooters to help with access management, deployment and maintenance of AI application. And apparently, it needs risk people to be involved to mitigate potential risks.
Time-box your experiment. Allocating a fixed time period to explore AI capabilities within a defined timeframe. Prototype, collect feedback, evaluate, and iterate. This approach helps in clarifying the decisions to be made by the end of the experiment.
I would like to end with a saying from Arthur Clarke:
When a distinguished but elderly scientist states that something is possible, he is almost certainly right. When he states that something is impossible, he is very probably wrong.

That said, I will not bet against AI. I think it is unwise to do so. Like all mature professions, in the beginning, every profession was once immature. So does AI. But we are living in an era of change. In the past decade, we have seen so many breakthroughs in deep learning, and it is not stopping any soon. Every few years, somebody just invents something crazy that makes you totally reconsider what is possible. In all honesty, I am over the moon with ChatGPT or Bard. I think they are amazing. The crucial question is not whether AI should be embraced but how. As GenAI is a new thing, there are still a lot of uncertainties we need to address. GenAI approach should support incremental adoption of the technology, while minimizing risks and facilitating learning.
I am sure I will learn more as I go, so more lessons will come.
Thanks for reading!
If you are keen on reading more of my writing but can’t choose which one, no worries, I have picked one for you:
Is ChatGPT Actually Intelligent?
_Maybe not…_towardsdatascience.com
Do You Understand Me? Human and Machine Intelligence
_Can we ever understand human intelligence and make computers intelligent in the same_pub.towardsai.net
References
- Medium post by Jeremy Arancio
- Generative AI Strategy — YouTube by Chip Huyen