Is ChatGPT Actually Intelligent?
Posted on
If you have been on any social media platform in the past months, I am sure you have heard about ChatGPT, Google Bard, Microsoft Bing and a myriad of new language models. All these new models, some can argue, are better writers than you and me and their English is definitely much better than mine 🥲 Every few years, somebody just invents something crazy that makes you totally reconsider what is possible. And in this article, we will be talking about the kind of invention that is rocking everyone in the world — yes, you guessed it — ChatGPT.

As we will increasingly rely on AI to do things for us, to make decisions for us, it is natural to ask whether AI is truly intelligent in the sense that its understanding of language mirrors our own, or that it is fundamentally different?
To make sense of it all, we are going to first look into how the Generative-Pretrained Transformer (GPT) and ChatGPT works, and then discuss what it means for an AI to be intelligent.
Understanding GPT Model
The GPT model, first proposed by OpenAI in their paper Improving Language Understanding by Generative Pre-Training, uses unsupervised pre-training followed by supervised fine-tuning on various language tasks.

The model architecture is based on Transformers, which has demonstrated robust performance in tasks such as machine translation and document generation. This model architecture was first introduced in the paper “Attention is all you need” by Google researchers. It provides an organized memory for managing long-term dependencies in text compared to recurrent neural networks and convolutional neural network, leading to better performance across a wide range of tasks.
It’s a prediction game
You can think of GPT model as a machine that is good at guessing what comes next. For example, if you give it the phrase “Instead of turning right, she turns…”, GPT might predict “left” or “back” or something else as the next word. How did it learn this? It does this by reading a large amount of existing text and learning how words tend to appear in context with other words and predicting the next most likely word that might appear in response to a request from users. Or to be precise, it learns how to interpret the positional encoding from the data. This means that we slap a number of each word in a sentence and as you train the model on a lot of text, it learns how to interpret the positional encoding of each word in a sentence.

Transformer
But it is not just guessing one word at a time, it is thinking about whole sentences and even paragraphs — and this is where the transformer architecture comes into the picture.
The “magic ingredient” that helps GPT make these predictions is the self-attention mechanism in transformer architecture. This mechanism helps the model determine the importance of each word in a sentence when predicting the next word. For instance, in the sentence “I walked my dog every day because it makes me…”, the word “dog” might indicate to GPT that the next word is likely related to dogs and feelings, such as “happy” or “relaxed”.
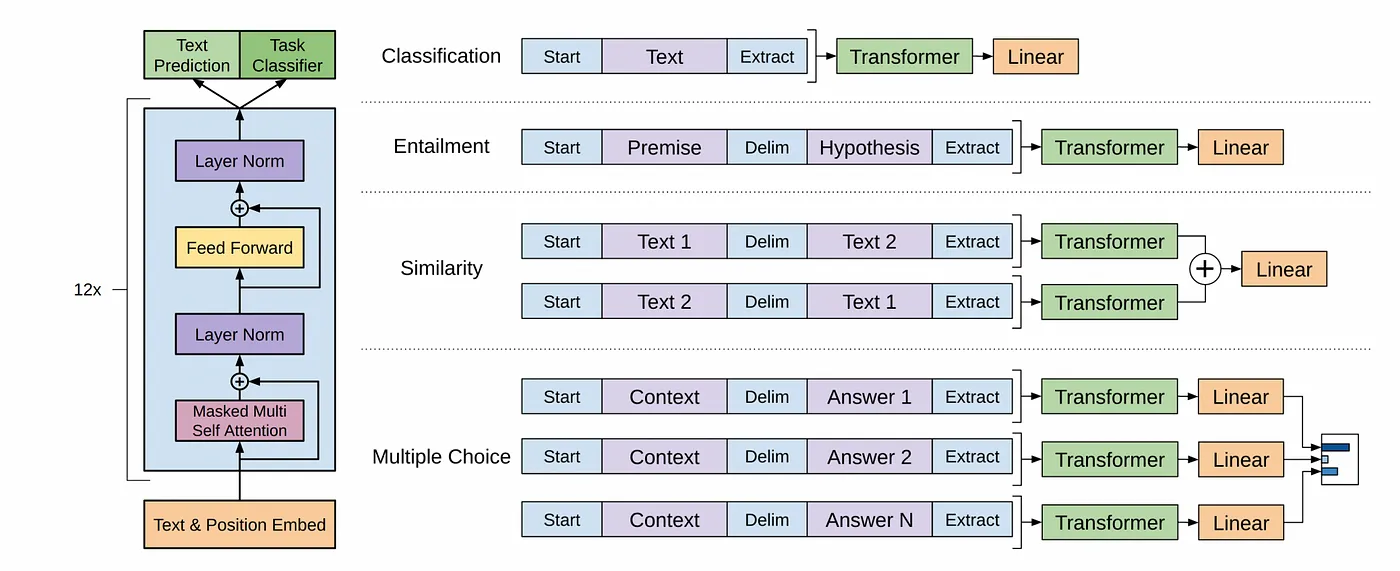
Self-attention mechanism
What is self-attention anyway? Let’s imagine a group of people (words) playing a game (sentence). In this game, each player represents a word in a sentence. Now, imagine that each player needs to determine how much attention they should pay to every other player on the field, including themselves, to predict the next move in the game.
In this context, self-attention is like each player communicating with every other player in the game. This communication allows them to assess the importance of every other player. Some players may seem highly significant (high attention) to you, while others may seem less so (low attention).
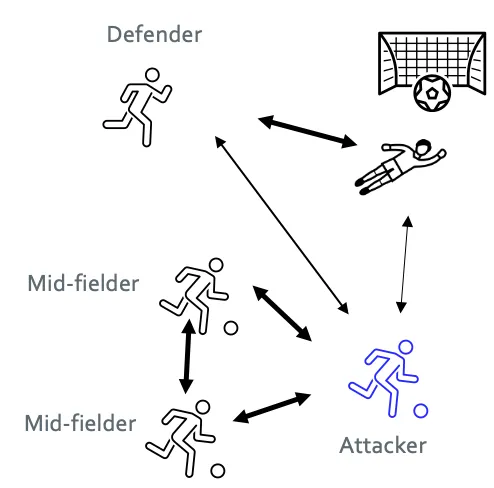
The level of importance is determined by how relevant each player is to the individual’s understanding of the game. For instance, if you’re a forward in a soccer game, you might find the midfielders highly relevant because they support your attacks, while the goalkeeper might seem less important to your immediate actions.
Now, imagine all of this happening simultaneously, with every single player communicating with all others to understand their relevance to the game. From this, each player calculates the significance score of every other player, including themselves.
In other words, each player isn’t just considering one other player at a time, but all other players on the field simultaneously. This simultaneous consideration is a key feature of the self-attention mechanism, and it’s what enables the model to capture complex relationships and dependencies between players in a game.
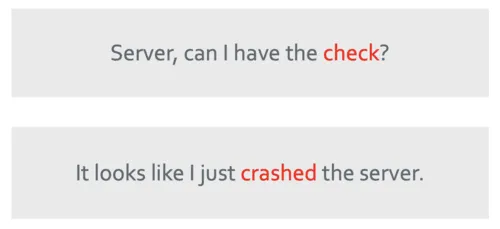
In the above example, the “word” server means very different things. Self-attention allows a model to understand a word in the context of the words around it. When the model processed the word “server” in the first sentence, it might be attending to the word “check” while in the second sentence, the server might be attending to the word “crashed” because the only way for the model to understand that the word “server” in the second sentence is a computer server/system is because of the word “crashed”. Meanwhile in the first sentence, the word server is attending itself to the word “check” because that is the only way the model can understand that the word “server” in the first sentence refers to a human.
The self-attention mechanism allows the GPT model to weigh the importance of each word in the sentence when predicting the next word by outputting the weights of each word as a vector, which will be used as the input for the prediction layer.
The prediction layer
The final part on top of the transformer layer is a linear layer that transforms the vector output of the Transformer layer into a set of logits — scores that the machine learning model assigns to predict the next word in a sentence. Each possible next token gets a logit (a score). These logits are then passed through a SoftMax function to get probabilities, and the word with the highest probability is selected as the prediction.
This process is akin to a prediction game. And because there are many possible words that could come next in our example sentence “Instead of turning right, she turns…”, there is an element of randomness in the way a model can respond. In many cases, the GPT models can answer the same question in different ways — which I think all of us have experienced while playing with ChatGPT.
How ChatGPT Works
Fine-tuning GPT model for dialogue
ChatGPT is a fine-tuned version of GPT-3.5 and has been developed in a way that allows it to understand and respond to user questions and instructions.
Training data
The three primary sources of information are (1) information that is publicly available on the internet, (2) information that is licensed from third parties, and (3) information that users or human trainers provide.
Training process
In this section, I will give a high-level explanation of the training process of ChatGPT, which involves supervised fine-tuning, the creation of a reward model for reinforcement learning, and fine-tuning with Proximal Policy Optimisation (PPO).
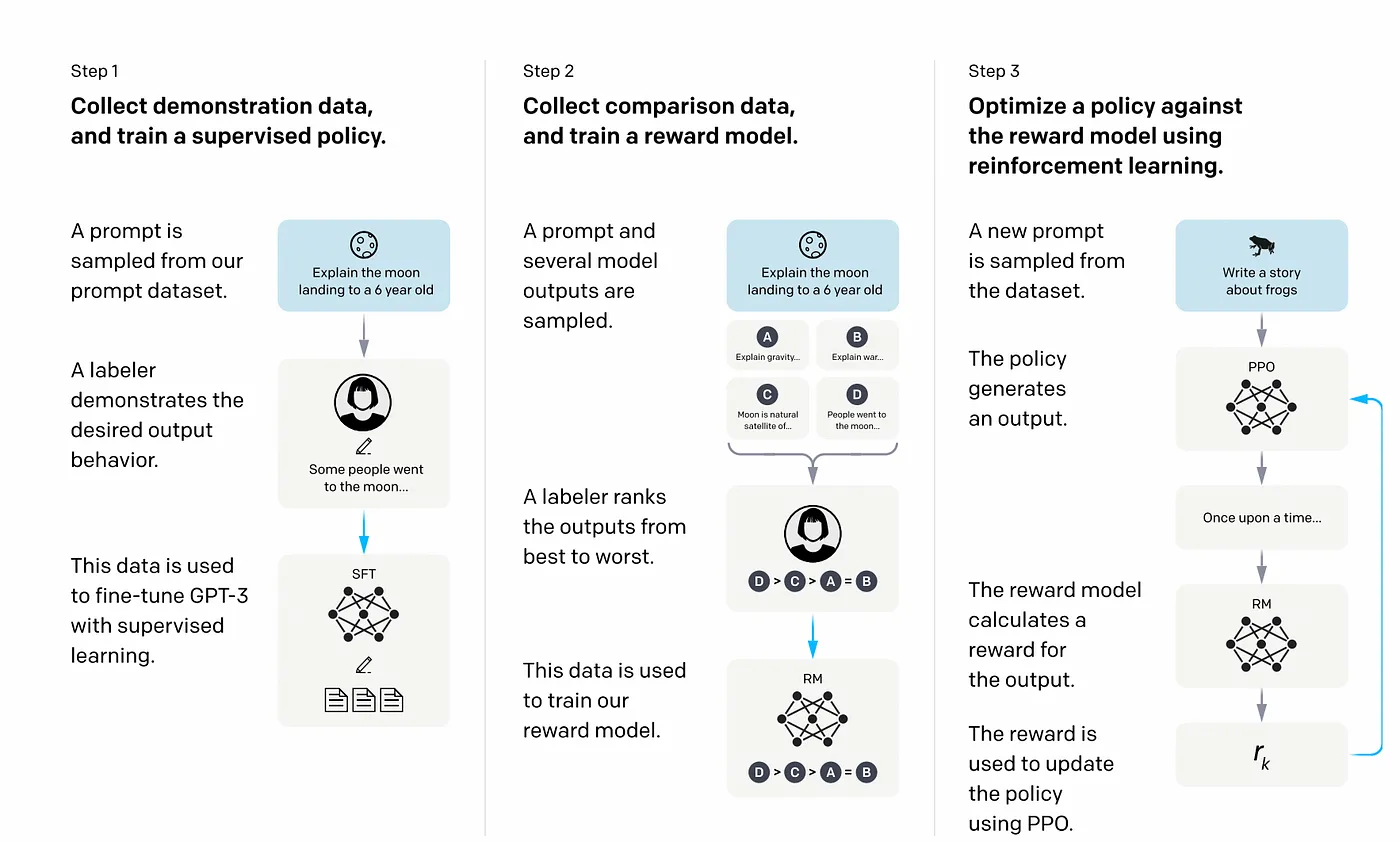
Step 1: Train a supervised learning model
In this step, the goal is to provide the model with examples of the desired behavior. This is done by having human AI trainers interact with the model.
This starts with collecting prompts from users. These prompts are then given to the AI trainers who generate responses that demonstrate the desired output behavior. This prompt-response labelled data is then used to fine-tune GPT-3.5, with the goal of learning to generate similar responses when presented with similar prompts in the future.
Step 2: Train a reward model for Reinforcement learning
The goal is to train a reward model that gives a score to the Supervised fine-tuned model outputs based on how desirable these outputs are for AI trainers. In other words, this reward model says something about the quality of the output based on the AI trainer’s preference.
Here’s how it works:
- A list of prompts is selected, and the supervised fine-tuned model generates multiple outputs for each prompt.
- AI trainers rank the outputs from best to worst. The result is a new labeled dataset, where the rankings are the labels.
- This new data is used to train a reward model that takes the output of the SFT model and ranks them in order of preference.
Step 3: Optimize the policy using the PPO algorithm
Reinforcement Learning (RL) is now applied to improve the policy by letting it optimize the reward model. In RL, a policy is a strategy or a set of rules that an agent follows to make decisions in an environment. It is a way for the agent to determine which action to take based on the current state.
RL is about learning from sequential interactions with the environment to optimize a long-term goal. Given the current input, you make a decision and the next input depends on your decisions. PPO (Proximal policy optimization) is the algorithm that is used by openAI to train agents in RL. In RL, the agent/AI learns from and updates the current policy directly, rather than learning only from past experiences (only training data). This means that PPO is continuously updating the current policy based on the actions that the agent is taking and the rewards it is receiving.
First, the trained supervised fine-tuned model in step 1 is used to initialize the PPO model. It will generate a response given a prompt. In the next stage, the reward model (built in step 2) produces a reward score for the response. Finally, the reward is fed back to the baseline model to update the parameters using the PPO algorithm that is supposed to increase the likelihood of better responses in the future. This process is iterated multiple times, with the model improving as it receives more feedback from the reward model and adjusts its parameters accordingly using PPO. This allows the model to learn from human feedback and improve its ability to generate future better responses.
Is GPT model actually “intelligent”?
While GPT model’s ability to generate human-like text is impressive, is its understanding of language the same or fundamentally different from human understanding?

A study from Stanford University attempt to understand whether pre-trained language models (PTLM) such as BERT or RobBERTa can understand definitions by finding the semantic relevance between contexts and definitions. The approach is that given a target word w in a context sentence c, the models are required to detect if a sentence g can be considered as a description of the definition of w. The PTLMs calculate the semantic similarity between the context embedding and the candidate definition embedding by using cosine similarity, which calculates the cosine of the angle between the two embeddings. The closer the cosine similarity is to 1, the more semantically similar the two embeddings. The studies found that PTLM struggles to understand when the definitions are abstract.
So, I guess the first question to address is what “understanding” and “intelligence” actually mean.
In this regard, the authors of On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? argue that the text, which is generated by large language models, lacks actual meaning and intention.
Traditionally, when two people engage in a conversation, they both try to understand each other’s beliefs, knowledge, experiences, and perspectives. The words we choose to use and what we say depend on our mental “picture” or understanding of the other person. Whether it is a child or an adult, a colleague or a family member, a partner, or someone we just met at the bus stop, we have certain assumptions about their thoughts and characteristics. Similarly, when we listen to someone else speaking, we automatically place their words in context based on our mental understanding of them, including their beliefs, knowledge, understanding, and intentions.

When a language model generates text, it doesn’t have any intention to communicate or consider the beliefs or thoughts of the person reading it. The training data used to create the model didn’t involve interacting with listeners or understanding their perspectives. Essentially, the language model can not understand and engage in meaningful communication as humans do.
Our human brains however are so influenced by our language that we interpret our communication with large language models as if they are trying to convey meaningful intent. And if one side of the communication lacks actual meaning, our understanding of deeper/inferred meaning becomes an illusion.
Looking at how the GPT model was built, it is obvious that these language models do not process information and generate text consciously. It was all a prediction game that foresees which words are coming next based on the patterns the models have seen from the training data. In addition, large language model like ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers because it does not have the common sense reasoning as we — humans do.
Can AI gain consciousness?
Human intelligence and understanding go hand in hand with consciousness — which is the ability to feel things, pain, joy, love and angers. Consciousness is linked to an organic body so a natural question to ask is would it be possible that non-organic systems can obtain consciousness? Because we know so little about human consciousness, we can’t rule out the possibility of computer developing consciousness. It is still an ongoing research, and whether AI can have consciousness or not, we might see in the coming decades. But perhaps one piece of good news is that at least for now we won’t have to yet deal with the science-fiction nightmare of AI obtaining consciousness and deciding to enslave and wipe out human :).
I think there is still a long way to go before machine intelligence becomes similar to human intelligence. “It is no longer in the realm of science fiction to imagine AI systems having feelings and even human-level consciousness,” says the BBC. Most experts agree that AI is nowhere near this level of sophistication but it is evolving at lightning speed and it is difficult to imagine how it will look like in the next few years.
What I believe is that we can say with reasonable confidence that current artificial intelligence models have developed a set of skills that are closely related to certain aspects of human intelligence. It might be the time for AI creators to invest more in understanding consciousness.
References
- Introducing ChatGPT (openai.com)
- How ChatGPT and Our Language Models Are Developed | OpenAI Help Center
- The inside story of how ChatGPT was built from the people who made it | MIT Technology Review
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877–1901.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., … & Lowe, R. (2022). Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 27730–27744.
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training.
- Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021, March). On the dangers of stochastic parrots: Can language models be too big?🦜. In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency (pp. 610–623).
- Are AIs actually intelligent?. If you have been on any social media… | by Telmo Subira Rodriguez | Jul, 2023 | Medium
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30