Working with PDFs: The best tools for extracting text, tables and images
Posted on
Lots of information comes from text data, for example in PDF documents. Handling PDFs can be particularly challenging, especially with tables and images.

If you work with single modality language model, then you probably already know that it doesn’t have the ability to directly interpret or “read” documents. It is only capable of handling one type of input, such as text-only or image-only. If you need to analyse images or infographics from PDFs, for downstream tasks e.g question-answering, you would typically use specialised packages for parsing the document. These tools can convert the document, the images and tables found in the document into text formats that can be understood and analysed by the model .
There are several good tools available for parsing PDF documents for your downstream tasks. In this article, we will go through a list of some good ones including PyPDF, Adobe PDF Services API, Camelot and Tabula.
First let’s install the relevant libraries:
!pip install pdfservices-sdk
!pip install openpyxl
!pip install camelot-py
!pip install opencv-python
!pip install tabula-py==2.9.0
!pip install jpype1
!pip install langchain
!pip install langchain-core==0.1.40
Extracting text, tables and images with PyPDF
Pypdf is a versatile and common library for parsing PDF documents. It can parse the documents including tables from the documents into plain text. Most of the time, the format of the table is also well preserved when using PyPDF to parse the document.

Parsing text and tables
Langchain document_loaders incorporate many different packages for reading various file formats including PyPDF. The following script processes the document using PyPDF and saves it in a dataframe format:
from langchain\_community.document\_loaders import PyPDFLoader
def extract\_text\_from\_file(df, file\_path):
file\_name = file\_path.split("/")\[-1\]
file\_type = file\_name.split(".")\[-1\]
if file\_type == "pdf":
loader = PyPDFLoader(file\_path)
else:
return df
text = ""
pages = loader.load\_and\_split()
for page in pages:
text += page.page\_content
\# Create a new df and concatenate
new\_row = pd.DataFrame({"file": \[file\_name\], "text": \[text\]})
df = pd.concat(\[df, new\_row\], ignore\_index=True)
return df
#Apply the function:
folder\_path = '../data/raw'
pathlist = Path(folder\_path).glob('\*.pdf')
filenames = \[\]
for file\_path in pathlist:
filename = os.path.basename(file\_path)
filenames.append(filename)
df = pd.DataFrame()
for filename in filenames:
file\_path = folder\_path + "/" + filename
file\_name = os.path.basename(file\_path)
\# Initialize an empty df
df\_file = pd.DataFrame(columns=\["file", "text"\])
try:
df\_file = extract\_text\_from\_file(df\_file, file\_path)
except Exception as e:
print("----Error: cannot extract text")
print(f"----error: {e}")
df = pd.concat(\[df, df\_file\])
df

You could also process each page separately, for example, in case you want to do a downstream question-answering task on each chunk/page. In that case, you can modify the script as following:
def extract\_text\_from\_file(df, file\_path):
file\_name = file\_path.split("/")\[-1\]
file\_type = file\_name.split(".")\[-1\]
if file\_type == "pdf":
loader = PyPDFLoader(file\_path)
elif file\_type == "docx":
loader = Docx2txtLoader(file\_path)
else:
return df
pages = loader.load\_and\_split()
for page\_number, page in enumerate(pages, start=1):
\# Each page's text is added as a new row in the DataFrame
new\_row = pd.DataFrame({
"file": \[file\_name\],
"page\_number": \[page\_number\],
"text": \[page.page\_content\]
})
df = pd.concat(\[df, new\_row\], ignore\_index=True)
return df

Extracting images
Every page of a PDF document can contain an arbitrary amount of images. Do you know that you could also extract all the images from the document using PyPDF?
The following block of codes extracts all the images from a pdf file and create a new folder to store the extracted images:
from pypdf import PdfReader
import os
output\_directory = '../data/processed/images/image\_pypdf'
if not os.path.exists(output\_directory):
os.mkdir(output\_directory)
reader = PdfReader("../data/raw/GPTsareGPTs.pdf")
for page in reader.pages:
for image in page.images:
with open(os.path.join(ouput\_directory,image.name), "wb") as fp:
fp.write(image.data)
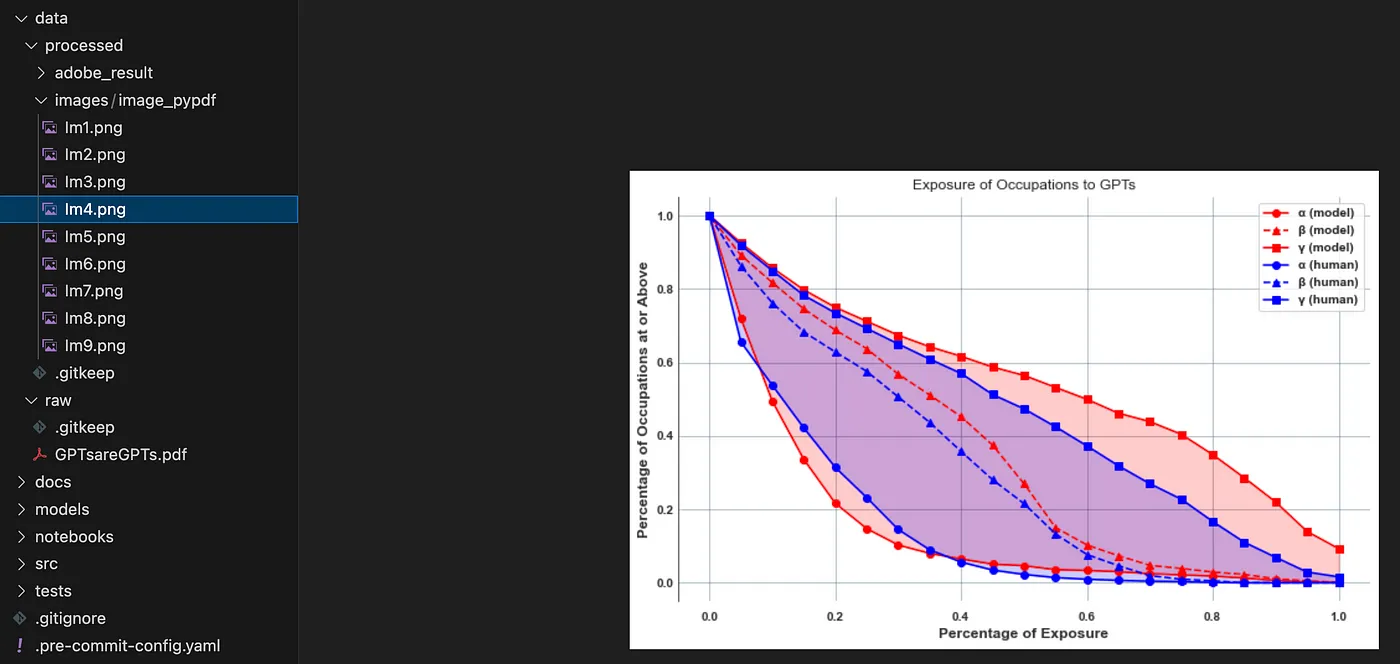
In the folder, you will find all the images in the PDF:
Extract text, tables and images with Adobe PDF Services API
The PDF Extract API (included with the PDF Services API) provides cloud-based capabilities for automatically extracting contents from PDF.
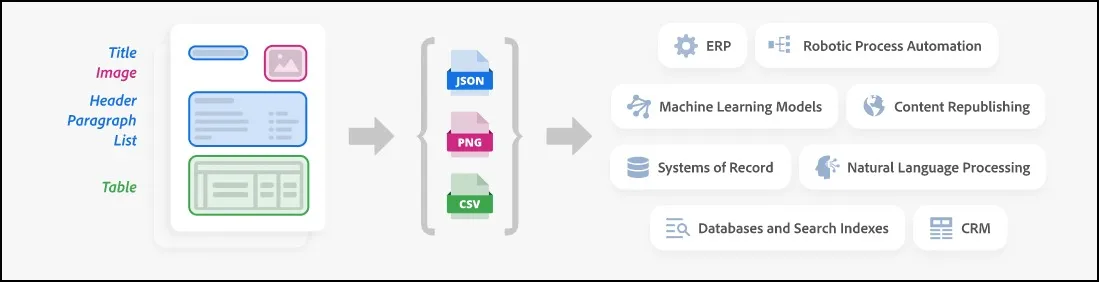
The APIs require an access_token to authorize the request. In order to use the access token, you need to create one. Once you have received your developer credential which includes client_id and client_secret in a json format, you can use it for processing your PDF. Let’st first import the relevant libraries:
from adobe.pdfservices.operation.auth.credentials import Credentials
from adobe.pdfservices.operation.exception.exceptions import ServiceApiException, ServiceUsageException, SdkException
from adobe.pdfservices.operation.execution\_context import ExecutionContext
from adobe.pdfservices.operation.io.file\_ref import FileRef
from adobe.pdfservices.operation.pdfops.extract\_pdf\_operation import ExtractPDFOperation
from adobe.pdfservices.operation.pdfops.options.extractpdf.extract\_pdf\_options import ExtractPDFOptions
from adobe.pdfservices.operation.pdfops.options.extractpdf.extract\_element\_type import ExtractElementType
from adobe.pdfservices.operation.pdfops.options.extractpdf.extract\_renditions\_element\_type import \\
ExtractRenditionsElementType
import os.path
import zipfile
import json
import pandas as pd
import re
import openpyxl
from datetime import datetime
The following script sets up Adobe PDF Services API with necessary credentials and processes the PDF file and saves the result in a zip file:
def adobeLoader(input\_pdf, output\_zip\_path,client\_id, client\_secret):
\# credentials instance.
credentials = Credentials.service\_principal\_credentials\_builder() \\
.with\_client\_id(client\_id) \\
.with\_client\_secret(client\_secret) \\
.build()
\# ereate executionContext
execution\_context = ExecutionContext.create(credentials)
extract\_pdf\_operation = ExtractPDFOperation.create\_new()
\# Set operation input from a source file.
source = FileRef.create\_from\_local\_file(input\_pdf)
extract\_pdf\_operation.set\_input(source)
\# Build ExtractPDF options
extract\_pdf\_options: ExtractPDFOptions = ExtractPDFOptions.builder() \\
.with\_elements\_to\_extract(\[ExtractElementType.TEXT, ExtractElementType.TABLES\]) \\
.with\_elements\_to\_extract\_renditions(\[ExtractRenditionsElementType.TABLES,
ExtractRenditionsElementType.FIGURES\]) \\
.build()
extract\_pdf\_operation.set\_options(extract\_pdf\_options)
\# Execute the operation.
result: FileRef = extract\_pdf\_operation.execute(execution\_context)
\# Save result to output path
if os.path.exists(output\_zip\_path):
os.remove(output\_zip\_path)
result.save\_as(output\_zip\_path)
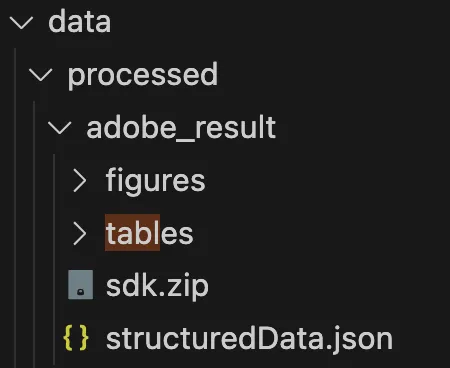
The output of this adobeLoader operation is a sdk.zip package containing the following:
- The structuredData.json file
- Text is stored in the json file and is extracted in contextual blocks — paragraphs, headings, lists, footnotes.
- “table” folder: Table data is delivered within the resulting JSON and also output in CSV and XLSX files. Tables are also output as PNG images allowing the table data to be visually validated.
- “figures” folder: Objects that are identified as figures or images are extracted as PNG files.
Now you can apply the function on your document:
\# Adobe output zip file path
input\_pdf = 'data/raw/GPTsareGPTs.pdf'
output\_zip\_path = 'data/processed/adobe\_result/sdk.zip'
output\_zipextract\_folder = 'data/processed/adobe\_result/'
\# Run the API
adobeLoader(input\_pdf, output\_zip\_path)
You can see that the “figures” folder returns all the images in my PDF document in .png format. The tables folder returns Excel sheets for tables which ensures high fidelity and accuracy together with the .png images for visual comparison purposes:

The quality of the extraction is premium in my opinion, especially when it comes to table extractions which are returned in excel format.
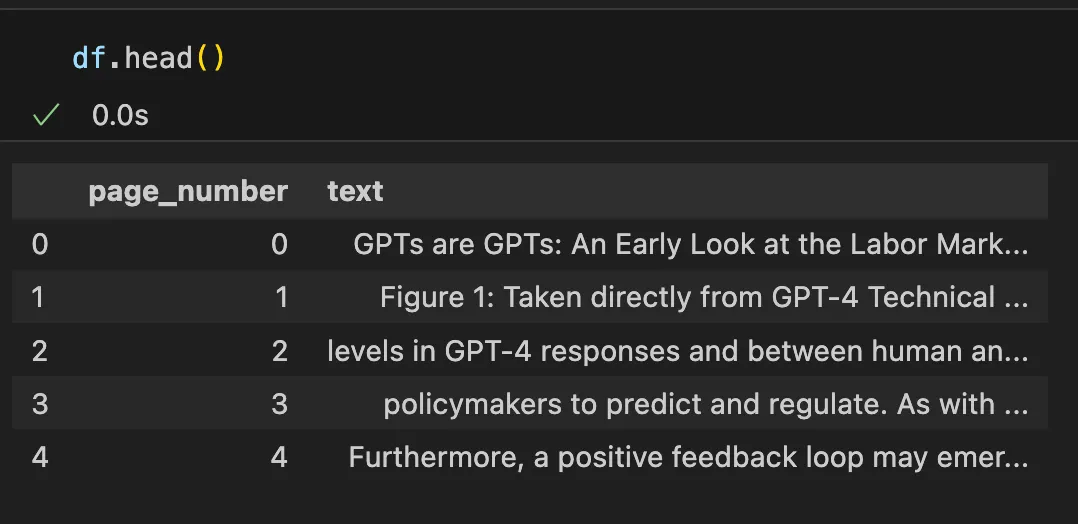
You could further process the structured JSON file structuredData.jsonto gather text and tables and organise this data into a pandas DataFrame for further downstream task:
Extracting tables with Camelot and Tabular
Tabula and Camelot are two Python library designed specifically for extracting tables from PDFs.
The following script processes the PDF document using either Tabula or Camelot, converting each table in the document into a JSON format, capturing both the actual table data and metadata such as table numbers and page numbers:
def extract\_tables(file\_path, pages="all", package):
if package == "camelot":
\# Extract tables with camelot
\# flavor could be 'stream' or 'lattice', for documents where tables do not have clear borders, the stream flavor is generally more appropriate.
tables = camelot.read\_pdf(file\_path, pages=pages, flavor="stream")
else:
tables = tabula.read\_pdf(file\_path, pages=pages, stream=True, silent=True)
\# Convert tables to JSON
tables\_json = \[\]
for idx, table in enumerate(tables):
if package == "camelot":
page\_number = table.parsing\_report\["page"\]
data = table.df.to\_json(orient="records")
else:
page\_number = ""
data = table.to\_json(orient="records")
data = {
"table\_number": idx,
"page\_number": page\_number,
"data": data,
}
tables\_json.append(data)
return tables\_json
Great! Now that we have the script to process the table, we can apply the function for the same Pdf document:
file\_path = '../data/raw/GPTsareGPTs.pdf'
file\_name = os.path.basename(file\_path)
df\_file = pd.DataFrame()
all\_tables = \[\]
for package in \["camelot", "tabula"\]:
try:
tables\_from\_package = extract\_tables(file\_path, pages="all", package=package) \# list of json
for table in tables\_from\_package:
all\_tables.append({"table": table, "source": package})
except Exception as e:
print("----Error: cannot extract table")
print(f"----error: {e}")
\# Now you can access each table along with its source
for entry in all\_tables:
print(f"Source: {entry\['source'\]}, Table: {entry\['table'\]}")
Here is an example of a table from the source PDF document:
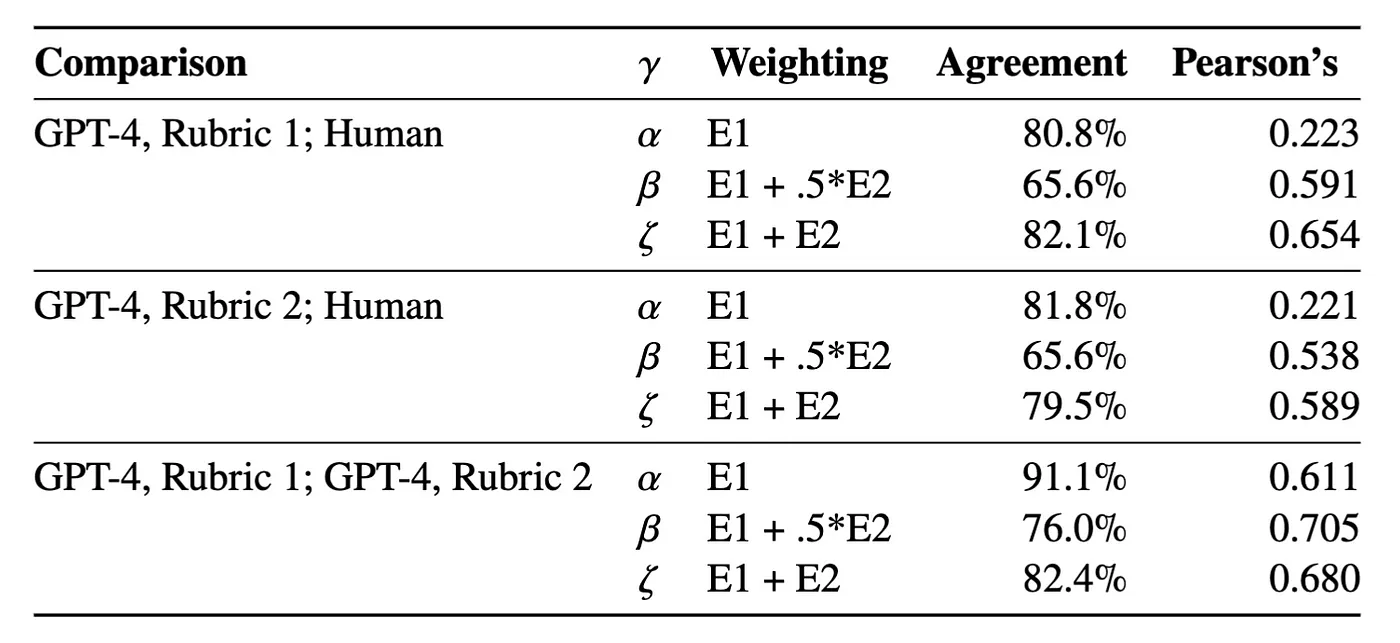
The output format of Camelot or Tabula operation is actually a string representation of a table, as presented in the json object below:
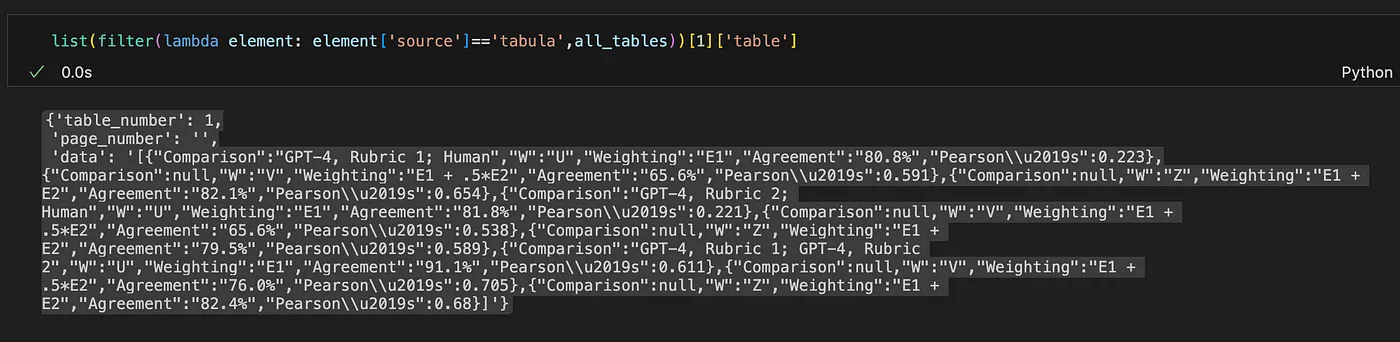
When you slice the [‘data’] key in the json object, VS Code seems to understand that it is a table format and show a table representation of the string, which looks exactly the same as in the source table in the PDF file. Tabula seems to detect the table correctly. Awesome!
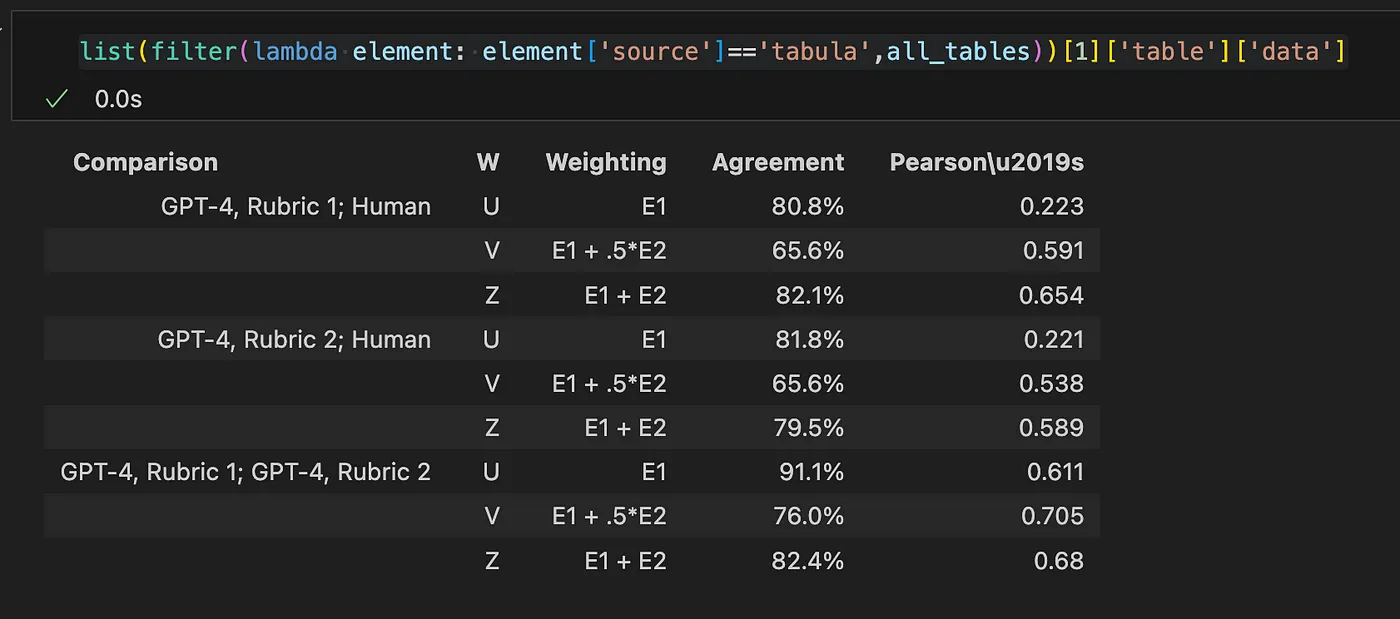
Now, let’s look at the output of Camelot. The following shows the json object of the same table.
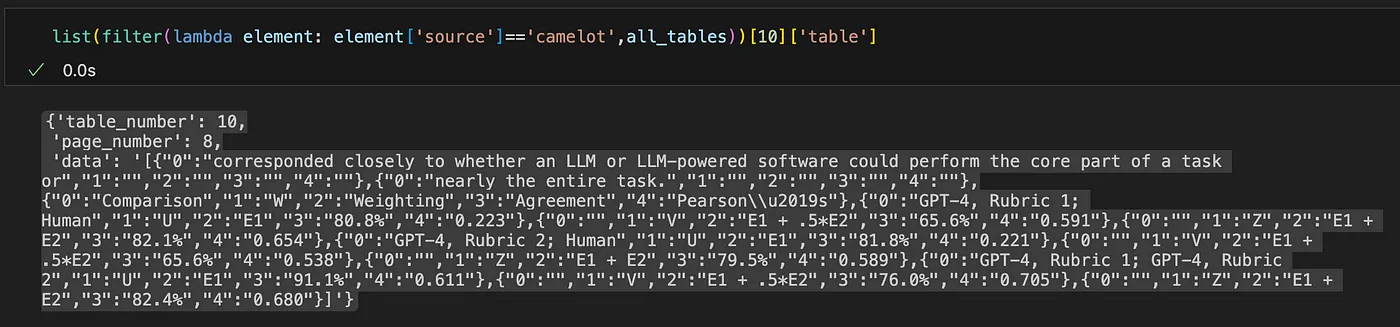
And the table presentation of the string:
In this example, both Tabula and Camelot were able to detect the table, however the output of Tabular is clean and mirror the original table from the PDF. Meanwhile Camelot appears to fail to detect the border of the table. It includes the text when it is too close to the table.
However, in another example when there are multiple tables present on a page, and there is no clear table border as in the following:
Camelot successfully detects both tables, whereas Tabula fails to detect either of them:
Comparison of different tools
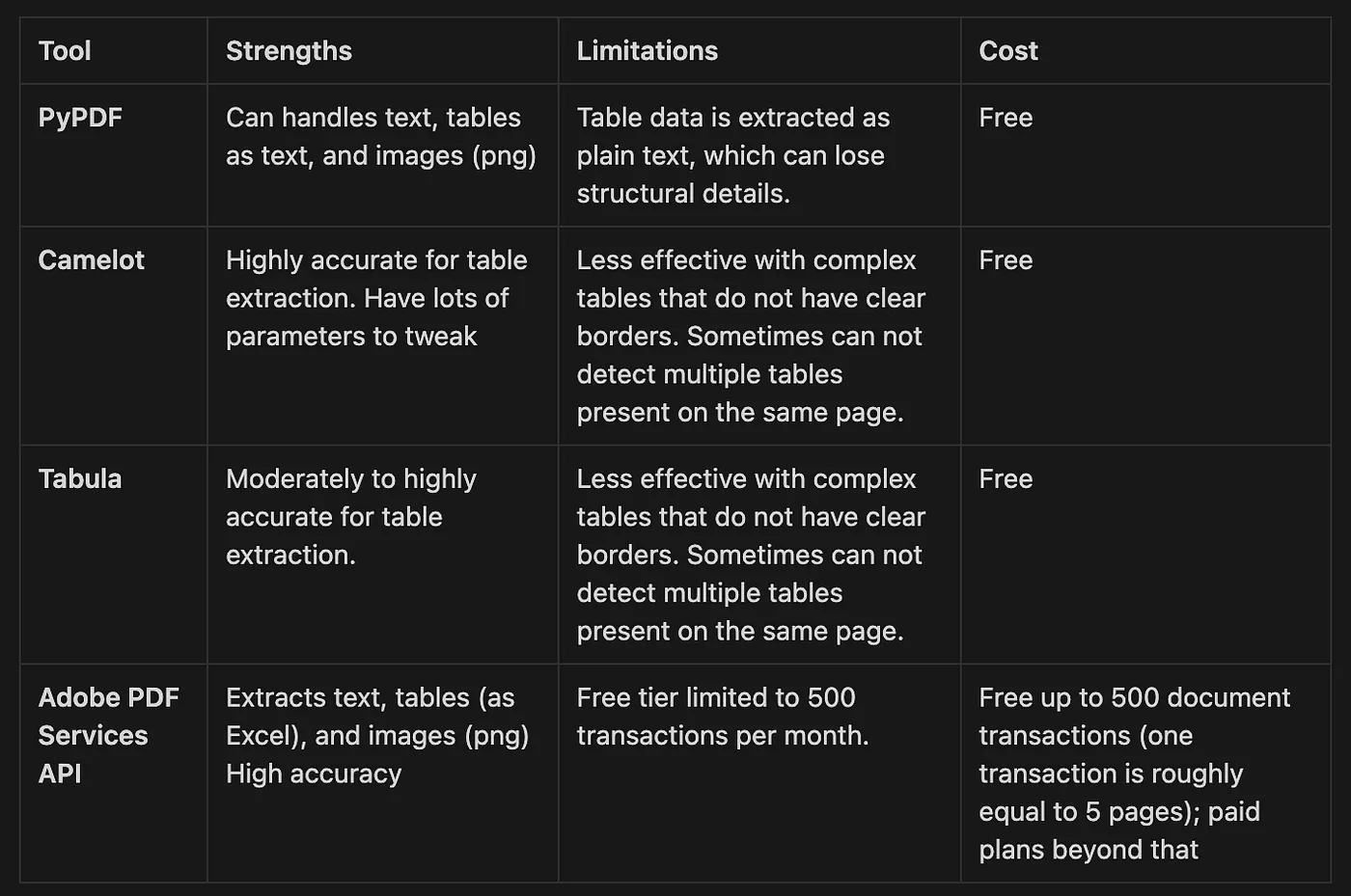
When thinking about which options to choose for parsing PDF documents, PyPDF is ideal for basic extraction needs where table structure is perhaps not a priority. It is completely free, making it suitable for users on a tight budget who need a simple solution with high accuracy for text and image extraction. In my experience, most of the time, format preservation of tables as text is acceptable.
Camelot and Tabula are are specialised for table extraction and are best suited for scenarios where table data extraction is required. They are completely free too and in my opinion would be good enough if you are okay with occasionally inaccuracies.
Adobe PDF Services API offers a very robust solution for businesses or applications where high accuracy in text, table, and image extraction are critical. However, there is no clear information on the API pricing. Here it says you need to contact Sales for a quotation. On this thread, it seems that the Adobe Extract API is rather expensive. Actually I would be willing to pay for actual usage since the quality of output extracted is premium! (Which makes sense because they are the one who created the PDF format, is not it? 😜)
Conclusion
In this article, we learnt four different tools for parsing PDF documents and extracting text, tables and images data from PDF files: PyPDF, Camelot, Tabula, and Adobe PDF Services API.
Thanks for reading. I hope it would be useful for you to efficiently transform PDF content into structured and actionable data.