Agentic document extraction, less diverse language and more!
What a week!
It felt like every day this week there was exciting news. A lot of new models were released: Anthropic’s Claude 3.7, OpenAI’s GPT4.5, Amazon’s Alexa+, Alibaba’s Wan2.1, Tencent’s Hunyuan Turbo S, Inception’s Mercury, xAI’s Grok 3, and probably a bunch more.
While all models compete comparatively on popular math and code benchmarks, the key differences the big AI players are focussing on: deep reasoning and speed. Inception’s Mercury model for example, is based on a diffusion architecture and generates tokens 3-10 times faster than 4o, while also being 10 times cheaper. GPT4.5, while much larger and slower than the previous generation models, is sold as having a much better “emotional intelligence”, and better aligned with what users actually want.
A new type of document extraction that uses agentic approach!
If you work with PDFs, you probably know how annoying it is to extract a simple table that spans over two pages using pyPDF 😅 You come to a point where you say, “you know what? Let’s do it manually this time”😂 That actually happens to me once! But not any more, ever since I figure out this ADOBE PDF Extraction API. Yes, it’s a paid service, but after trying so many other packages, I found nothing that comes close to Adobe’s performance, especially with parsing tables.
But now there’s a new player in town: Agentic Document Extraction from Landing AI. It uses an “agentic” approach to parse documents, which sounds super creative (though I’m not entirely sure why document extraction needs to be agentic).
The website doesn’t provide specific details on how this agentic approach actually works. However, in a post by Andrew Ng, he mentioned that “the agentic approach can summarize images/tables and extract details from these elements. The agent can use reasoning to combine and connect these elements, maintaining the document’s hierarchical structure and providing more contextually aware outputs. For example, if your document contains flowcharts.
I’m making a guess here, but I think the agent might dynamically choose different modules or processing functions based on the document’s components. For example, if it detects a table, it might automatically switch to a table-parsing function—pretty smart, right?
So, of course, I had to test it out. And wow, I was genuinely impressed! The table parsing is spot-on, totally on par with Adobe’s API. But what really blew me away was the image parsing. Most PDF processing tools just extract images, leaving you to handle OCR or pass them through a vision model to get the data. Honestly, I’ve never been entirely happy with those results. And this tool from landing AI did an incredible job in parsing data from image into text. Woa! I think it is really a game changing for use cases that need to process complicated PDFs.
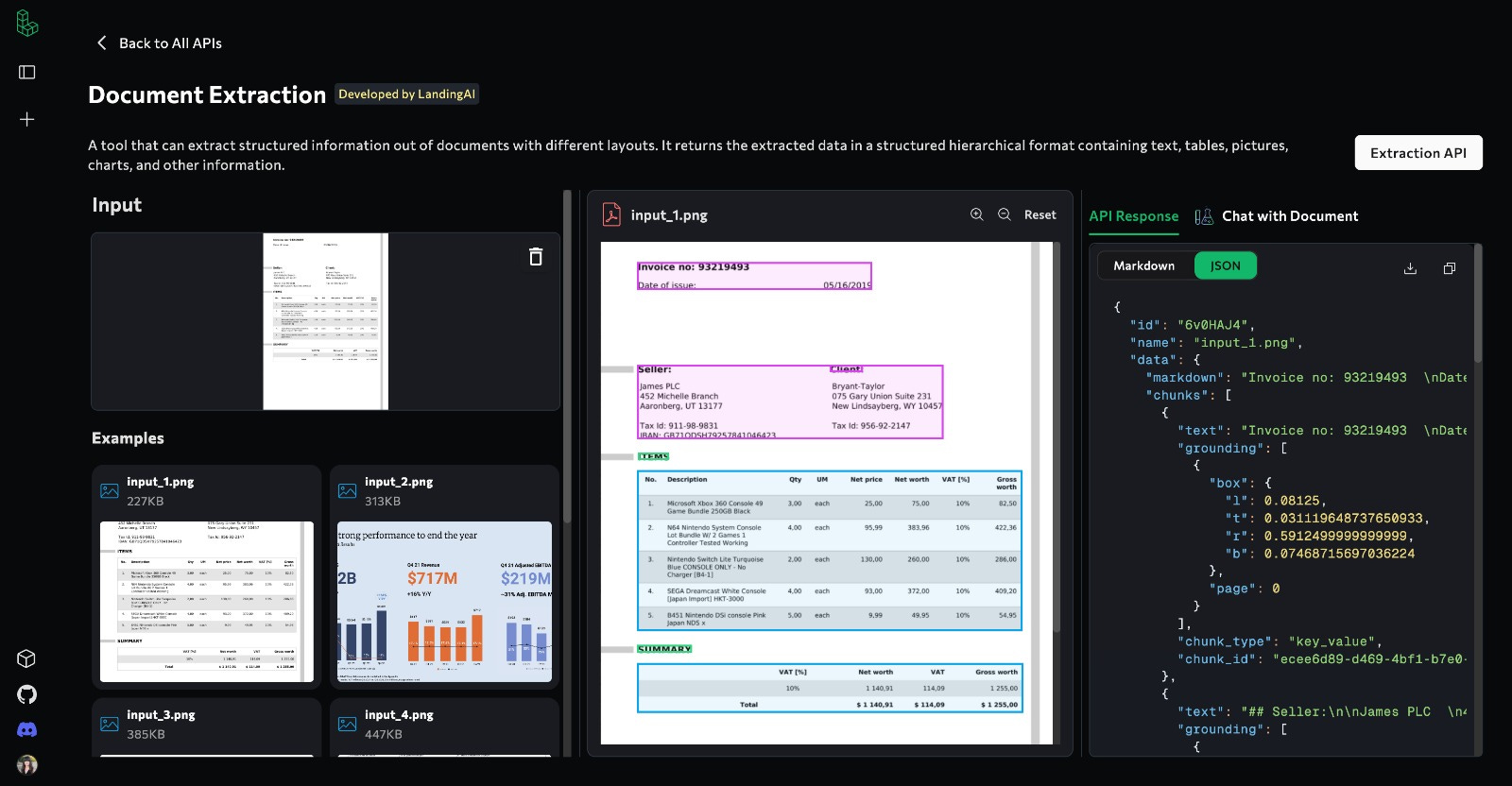
A preview of Landing AI’s document extraction. Structured data is obtained from highlighted PDF and can be returned in either markdown or json format.
AI is making our written language less diverse
Have you ever wondered if there’s a measurable effect that large language models have had on online written text? Si et al. from Stanford University conducted a very interesting research on exactly this topic. By using AI detection tools and various statistical properties of text, they highlight a significant shift on how language is used in different online sources.
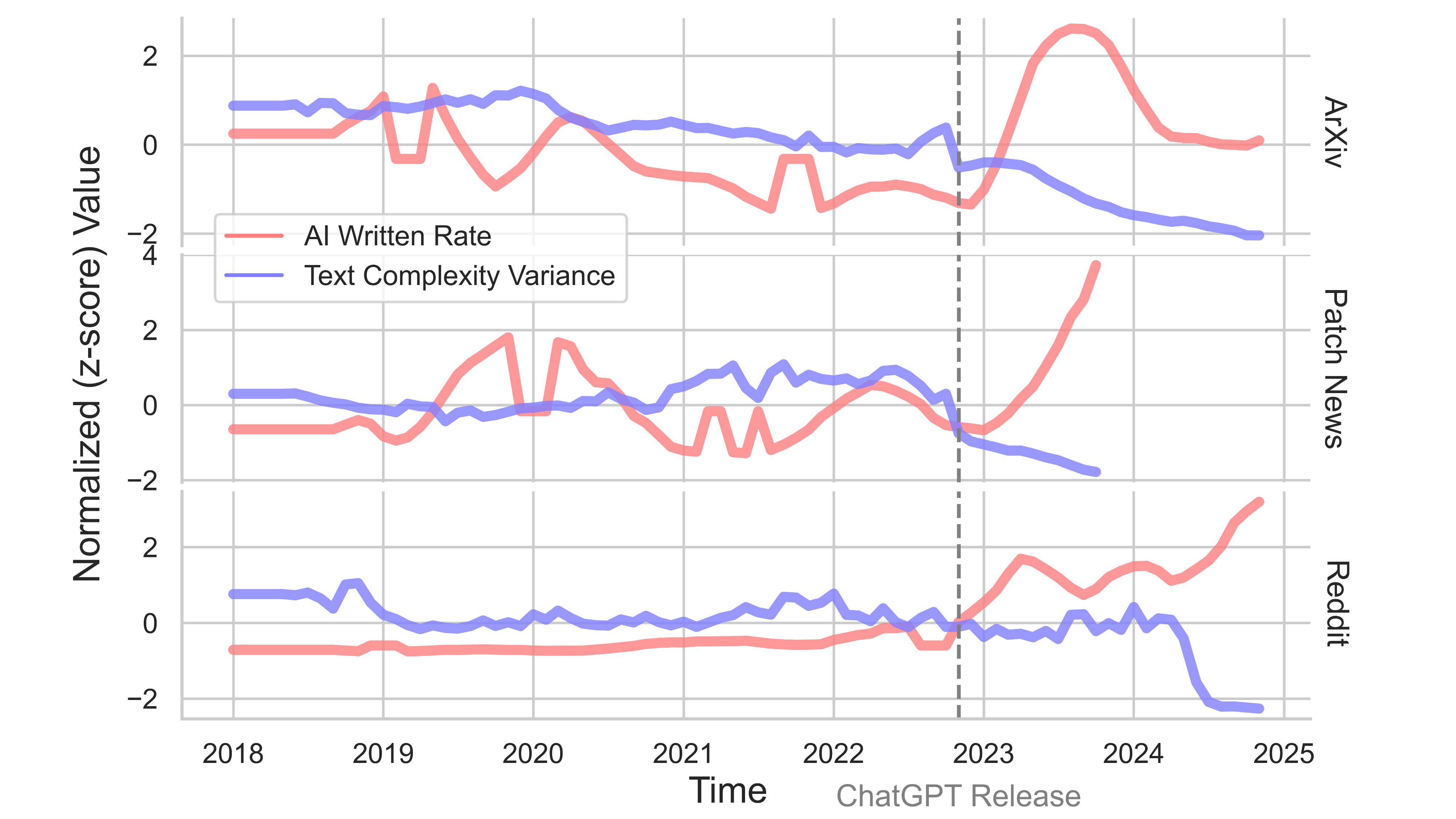
AI detection rate and language diversity on arXiv, news reports written on Patch News, and short stories written in the WritingPrompts subreddit.
Overall, we see that the text complexity goes down in all three sources, albeit with different adoption rates. The textual complexity here is a combination of different metrics that say something about the “richness” of text, for example the number of unique words, or the average length between syntactic dependencies in the text.
As written text gets more homogeneous due to AI, it will become more difficult to extract the author’s personal traits and characteristics from the text. The researchers continued their investigation and show that text that was rewritten by AI, reduces our ability to infer some of the characteristics from the original authors, such as gender, age, personality, empathy, and morality. This indicates that not only does text become more homogeneous, it also becomes less distinctive to personal traits. While male authors use less social words than female authors, and extraverts use more friend-related words than introverts, after rewriting the original text using AI all these patterns and cues are reduces significantly.
As the authors point out, written text is not only a medium to share information, it also
“… paint a portrait of who we are, where we belong, and how we connect with the world around us, solidifying language’s central place in the human story. This richness, stemming from the inherent diversity of human expression, allows us to glean insights into individual and societal characteristics.”
What we’ve been reading/watching this week
(livestream) Anthropic connected Claude 3.7 to a gameboy emulator and plays Pokemon red, live on twitch.
(article) Researchers showed that transformers, the underlying architecture of today’s large language models, are Turing complete: for any computable function there exists a prompt for which that transformer will compute that function.
(article) Remember when Cisco announced they effortlessly jailbreaked DeepSeek? They’ve published all the details in this paper.
(artice) Combining traditional OCR techniques, with vision models boosts transcription of 19th century printed texts.
(article) Though research ideas created by AI are more novel than those by experts, they are (slightly) less feasible.
