Inside the mind of AI | And when less data might be better

What if we could read the thoughts of a language model before it speaks?
Large language models don’t just learn statistics — they build internal organization of concepts as human do?
Often, we treat large language models like black boxes — you type something in, and comes a response. A common understanding of how LLMs make predictions is by statistically imitating their training data, generating the next token based on learned patterns.
Mathematically, we know exactly what the model is doing: each neuron is just doing simple calculations. But why those mathematical operations result in the intelligent and complex behaviors like writing code, understanding metaphors, or reasoning through moral conflicts — remains a mystery. Without understanding how it works internally, it’s hard to trust that these systems. Not having enough trust is probably #1 roadblocks for companies to adopt AI.
One approach to the interpretability model is to ”open” the black box - the internal state of the model— which is, what the model is “thinking” before writing its response. This is the first step to understand what the individual components of the language models like neurons and attention heads are doing.
A while ago, Anthropic published a research in which they studied Claude Sonnet and discovered millions of “features” inside the model — patterns of combination of neurons that often activate together. These features represent everything from legal disclaimers to scam emails to emotional tension.
But just “opening” the black box is not enough because it consists of a long list of numbers (neuron activations) without a clear meaning.
So they have matched these patterns of neuron activations, to human-interpretable concepts through a technique called “dictionary learning” and measure a kind of “distance” between features based on which neurons appeared in their activation patterns. This allowed looking for features that are “close” to each other.
For example, in the following fascinating visual, when looking at features associated with “inner conflict,” they found nearby features related to “Guilt”, “between a rock”, “Catch-22” situations, or loyalty struggles. The model’s internal structure seems to mirror human-like notions of conceptual similarity.
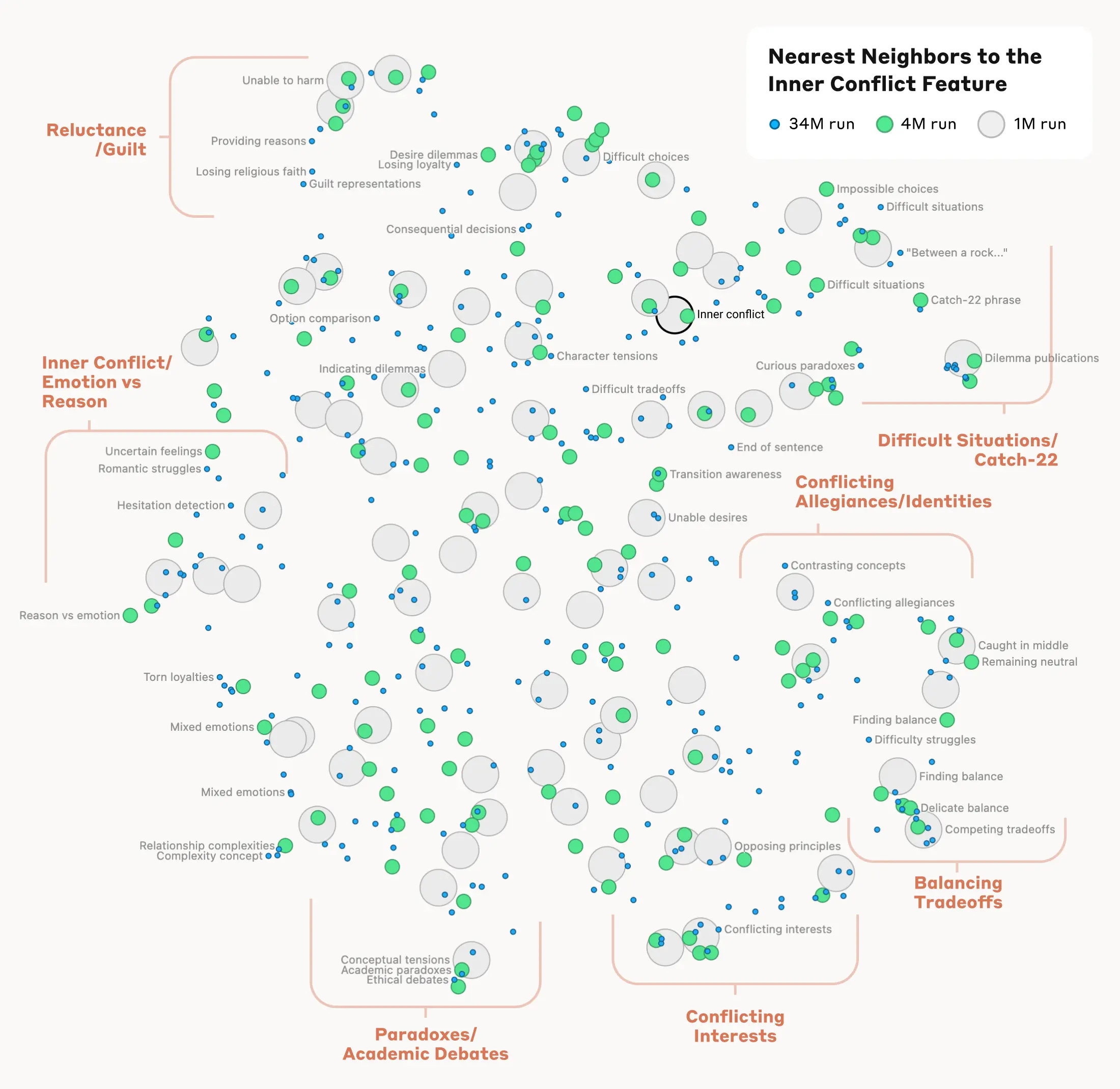
This is fascinating! Does this mean that instead of simple next token predictions, the language models have been able to build rich internal representations of concepts and with the right tools, we’re starting to decode them?
When less data leads to better performance?
AI models are trained on data. The 2010s and early 2020s were the age of scaling. Deep learning worked. The formula for success was clear: feed a massive dataset into a huge neural network and train it for a long time.
The last few years we see the trend where each new performance breakthrough in AI is due to ever larger models trained on ever larger amounts of data. Recently, smaller models appeared that perform on par with larger ones, breaking this trend.
While models can get bigger and compute is stronger, there is only 1 internet. We have exhausted all the data and people start talking about going synthetic.
But what if I told you we don’t need that much data after all, and that: better performing models were trained on less data?
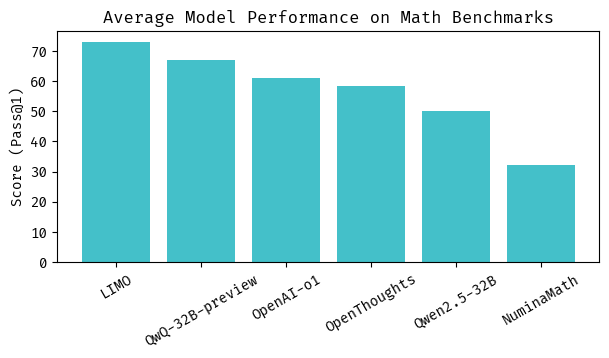
Two recent papers show exactly this. The first paper, LIMO: Less is More for Reasoning, builds on the assumption that foundational models contain enough domain knowledge and already have a hidden reasoning capabilities that just need to be uncovered. Then, instead of passing large amounts (~100k) of reasoning examples during some reinforcement learning scheme that forces a model to learn how to reason from the ground up, we now pass only a relative small amount (~800) of high quality reasoning examples for a quick finetuning. The result? A model that outperforms both o1 and R1 on various math benchmarks, while using 100x less training data.
The second paper, A Few Tokens Are All You Need, shows that when models reason, for most of the possible solutions that the AI might choose from, the starting tokens are usually the same. If that is the case, do we need the model to generate a full response during training? Surprisingly… no. The authors show that just 8-32 tokens is enough to accept/reject the output during fine-tuning. Consequently, the training time is reduced by over 75%, without losing any performance of the final finetuned model.
This is a very interesting shift in perspective! Less, it turns out, might truly be more.
What we’ve been reading/watching this week
- We got ourselves the book Consideration on the AI Endgame by Roman Yampolski and Soenke Ziesche. A quick look into the looks brings us immediately to the concept of “ikigai” risk. This a perfect read for our trip to Japan next month, you know “ikigai” is a Japanese concept for “a reason for being”, don’t you?
- In a recent interview, Yann LeCun raised scepticism about whether LLMs can reason and truly understand our world, and hints at another “AI winter” if we do not start investing in alternative architectures compatible with “true” AGI.
- Scientific American published an opinion post warning about the ever increasing carbon footprint that AI brings to the world.
- How fast is AI improving? By defining the complexity of a task as how long it would take for an expert to solve it, researchers found that the ability for an AI to complete an ever increasing complex task, doubles every 7 months, projecting that by 2030 AI can easily solve problems that would require an expert a week to solve.
That’s it for now. Catch you soon!
With love,
Lan and Robert
