Evaluate the LLM-based Evaluator, Google reclaims the AI Throne?
The initial cost of setting a robust automated evals pays dividends
We previously briefly wrote about the importance and difficulty of LLM evals.
Human evaluation is cubersome and unscalable, but building robust automated evals is also seen as a massive investment (e.g. creating 1000 of examples and designing metrics and validating approaches) and there is never a convenient moment to put in that up-front cost. For many teams, it may make more sense to rely solely on human judges than figuring out how to build automated evaluation system.
Because of that, many end up having humans check hundreds of example AI outputs with every small update to judge if it improved the system.
That just does not work.
Then you realize, the initial cost of setting an a robust automated evals pays dividends through faster iteration cycles.
But it is far from easy to build a robust automated evals pipeline.
While LLMs are increasingly used to evaluate LLM-generated outputs, they inherit all the problems of the LLMs they evaluate. The details of getting the automated evals to work (such as the prompts, the metrics ) are also tricky to get right.
How can we make sure our LLM-based evaluation pipeline is sound? One way to do that is to make sure the LLM-based evaluation is aligned with human evaluation.
The point is, automated evals does not have to replace but rather complement manual evaluations. As with many things in AI, we often don’t get it right the first time. Over time, you can finetune your evaluation pipeline ( to close the gap between the evals’ output and human judgments).
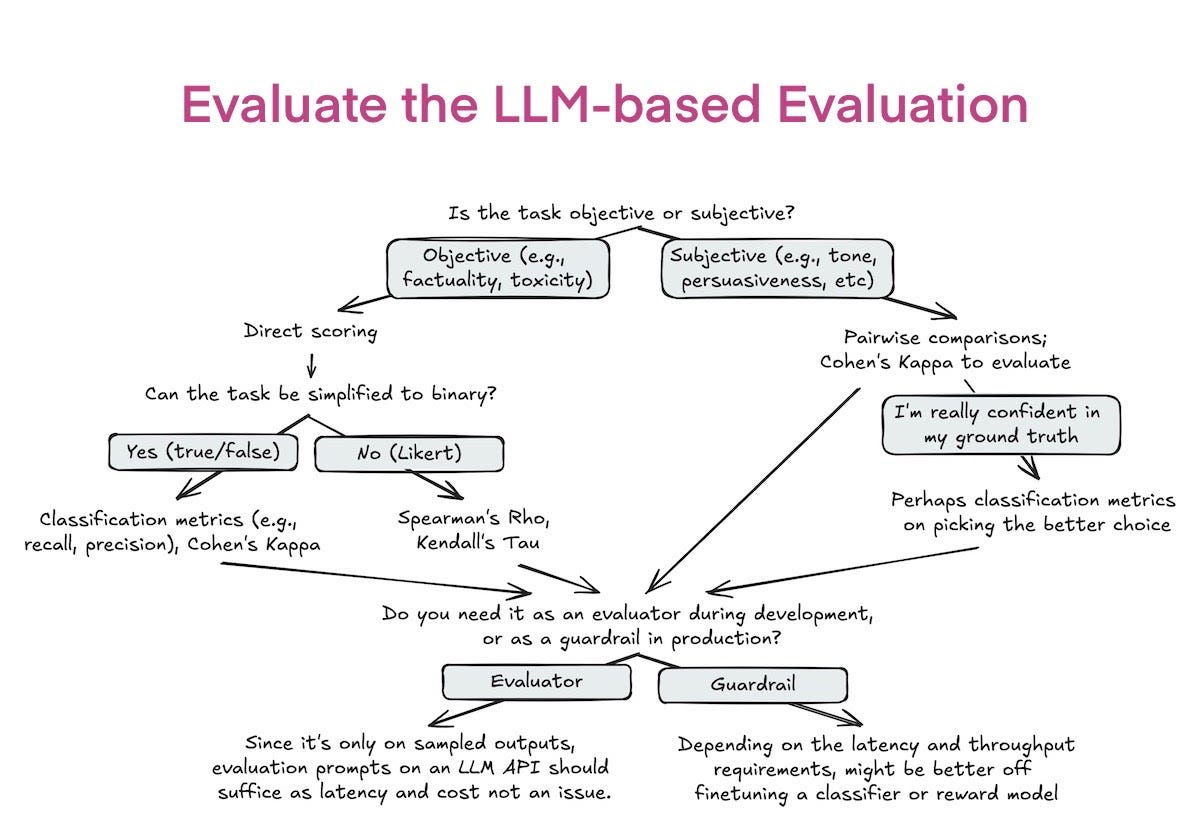
Define evaluation criteria
Often, the hardest part of evaluation isn’t determining whether an output is good, but rather what good means. Before evaluating your application, think about what makes a good response.
For example, for a information retrieval application, a good response might be defined using three criteria:
- Relevance: the response is relevant to the user’s query.
- Factual consistency: the response is factually consistent with the context.
- Reasoning quality: Is the logic used to derive the answer sound?
To evaluate, for instance, if an answer is factually consistent with a given context, one approach is to use a binary scoring system: 0 for factual inconsistency and 1 for factual consistency. On this scoring system, create a rubric with examples and clear guildline what it means when a response deserves a 1 and when it receives a 0.
Running your LLM-based evaluation pipeline and comparing that with the human evaluation
Examining the resulting confusion matrix can reveal the level of human-AI agreement. Overall, in my example, it looks quite good!
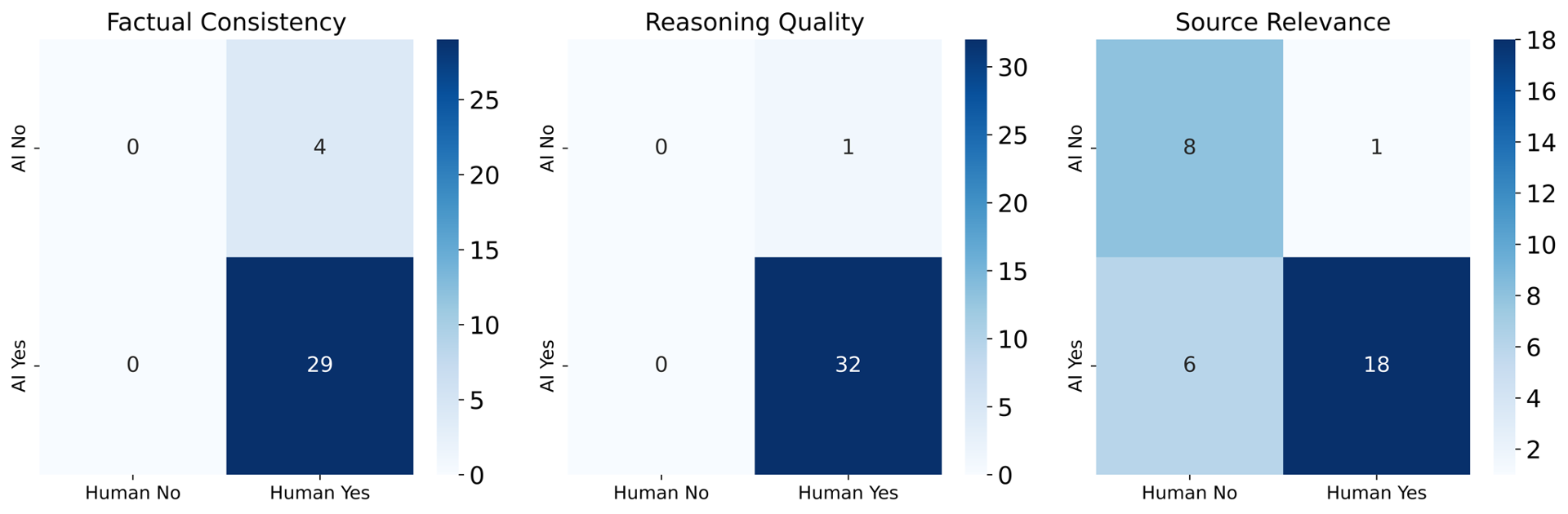
From there, you can use classification metrics like precision, recall, and accuracy to measure the alignment score between human and AI judgments.
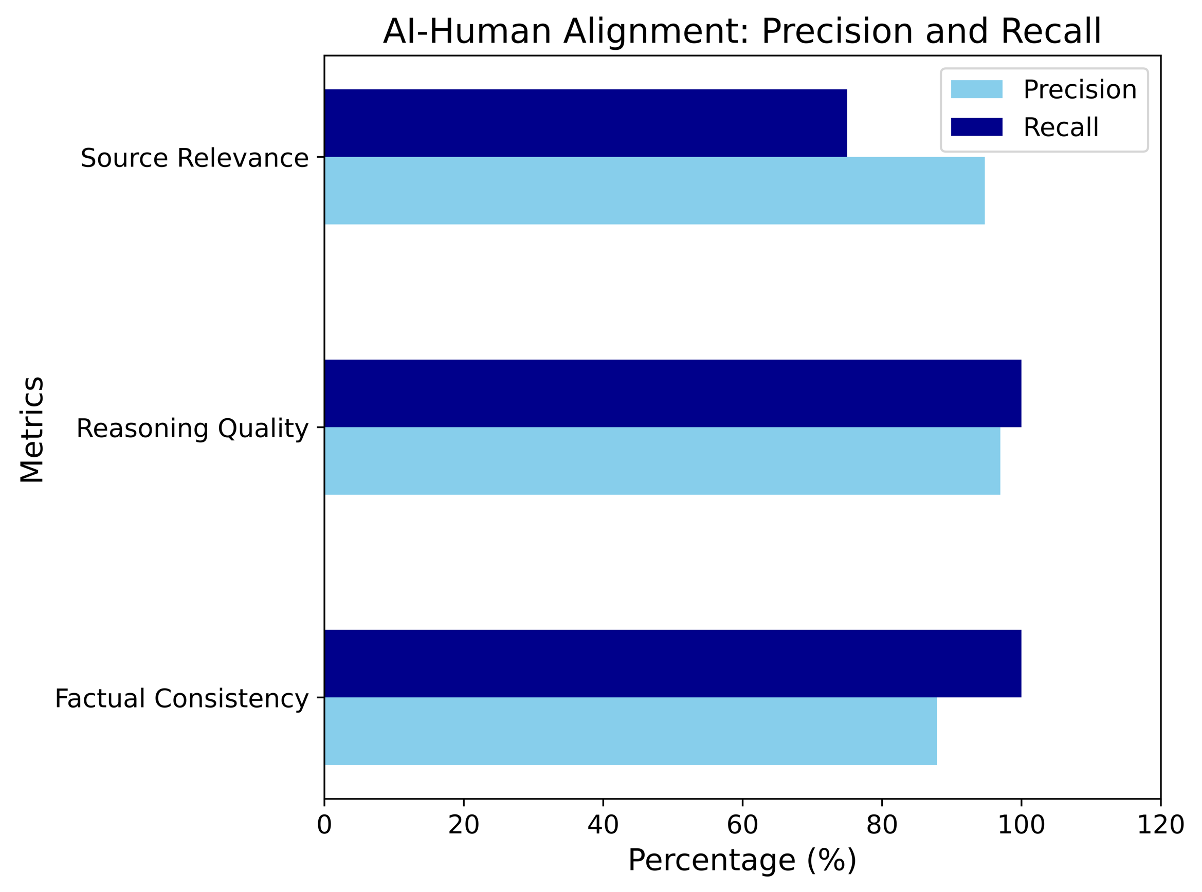
The human-AI alignment scores look so good, your stakeholders are probably happy! How about you? Sadly, not yet! There is one problem here.
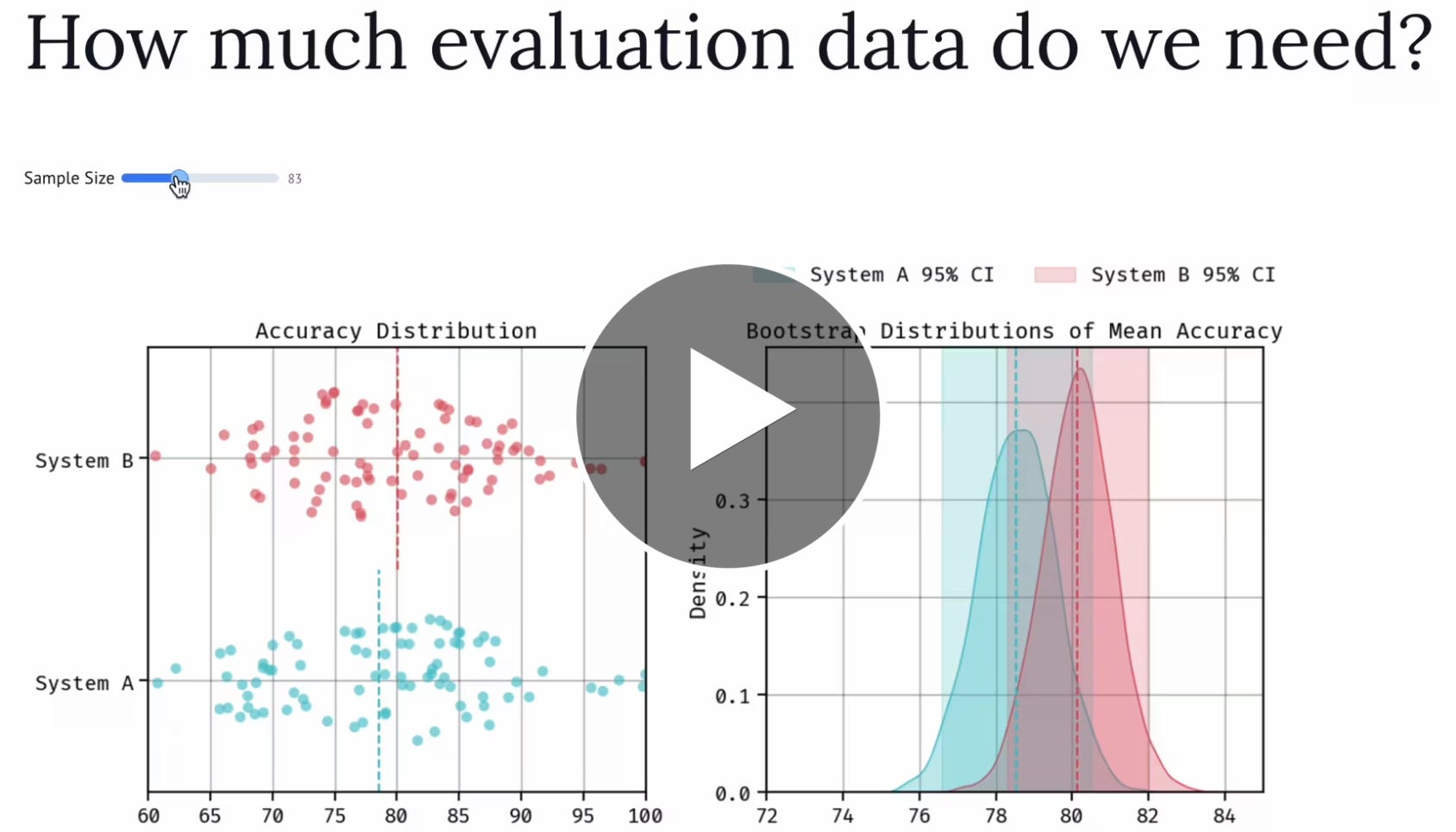
How much annotated evaluation is needed?
Yes, you are right — we have very little human-annotated data in my dataset (only 33 samples).
So how much data is sufficient to ensure our evaluation pipeline is good?
Let me ask you a question, if you are going to buy something on amazon and look at these two reviews, which one do you trust more? (We know the right answer, don’t we? 😉 )

Imagine, you need to evaluate and compare different AI evaluation pipelines and need to curate a set of annotated examples to evaluate your application.
How much evaluation data do we actually need to differentiate the performance of two pipelines? Is 50 examples enough? Maybe 500? maybe even 10.000?
One way to get the answer, is by calculating the confidence interval of the performance of each of the two pipelines. Do the two intervals overlap? You’re gonna need more data. Usually, if you want to shrink an interval by a factor 2, you’ll need 4 times more data.
The easiest way of calculating the confidence interval is through bootstrapping. Bootstrapping is a simple technique that allows you to estimate the uncertainty of statistics, such as your model’s performance (e.g. RMSE, accuracy, F1…etc), by resampling your data with replacement. From your existing data, you create many resampled versions of the existing dataset and then estimate the uncertainty of the model’s performance on these new datasets.
Just like building AI models, we often don’t get it right the first time. We can build automated evals the same way. Start building simple automated evals early in the project allows faster iteration and as these evaluations mature, their early implementation provides ongoing benefits throughout the development process and for other projects.
Of course, don’t be afraid to fall back on human evaluation as the North Star when in doubt.
Is Google Reclaiming the AI Throne? The AI race just becomes much more interesting
A couple of weeks ago, Google dropped its most intelligent model Gemini 2.5 Pro, followed by Gemini 2.5 Flash, a version with lower latency fews days ago. They are both available in Google AI studio.
Gemini 2.5 family models are thinking models, designed to tackle complex problems. Gemini 2.5 Pro leads common benchmarks by meaningful margins and showcases strong reasoning and code capabilities.
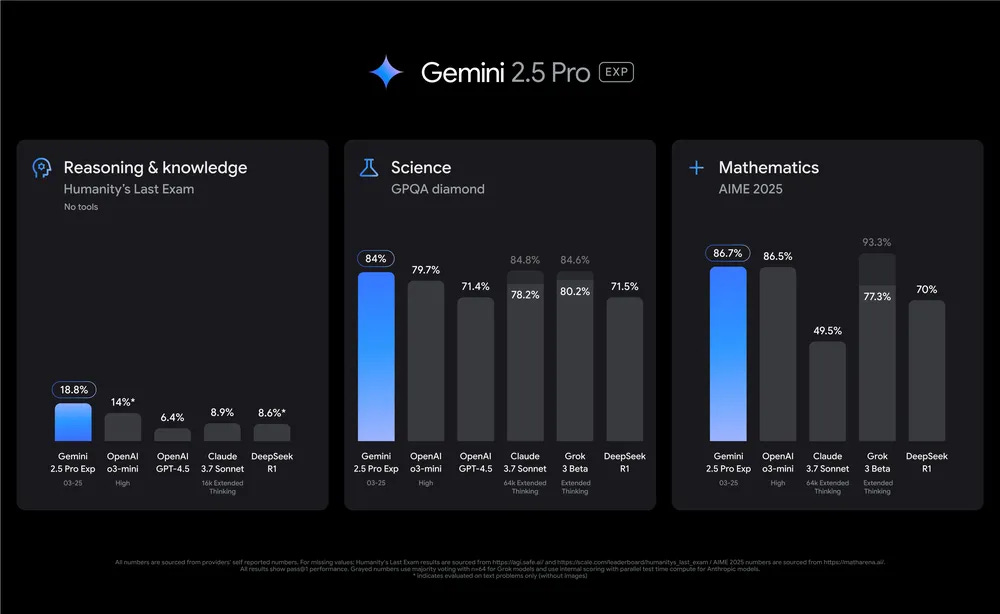
Gemini 2.5 is multimodal model and offer a gigantic context window of 1 million token context window ( and 2 million coming soon!!). Because of that, it can comprehend vast datasets and even entire code repositories. Some people start talking again about RAG is dead, but let’s save that for another newsletter.
Just a month ago, Google also released Gemma 3, a family of lightweight multimodal models delivering performance comparable to larger models while running on a single GPU or TPU.
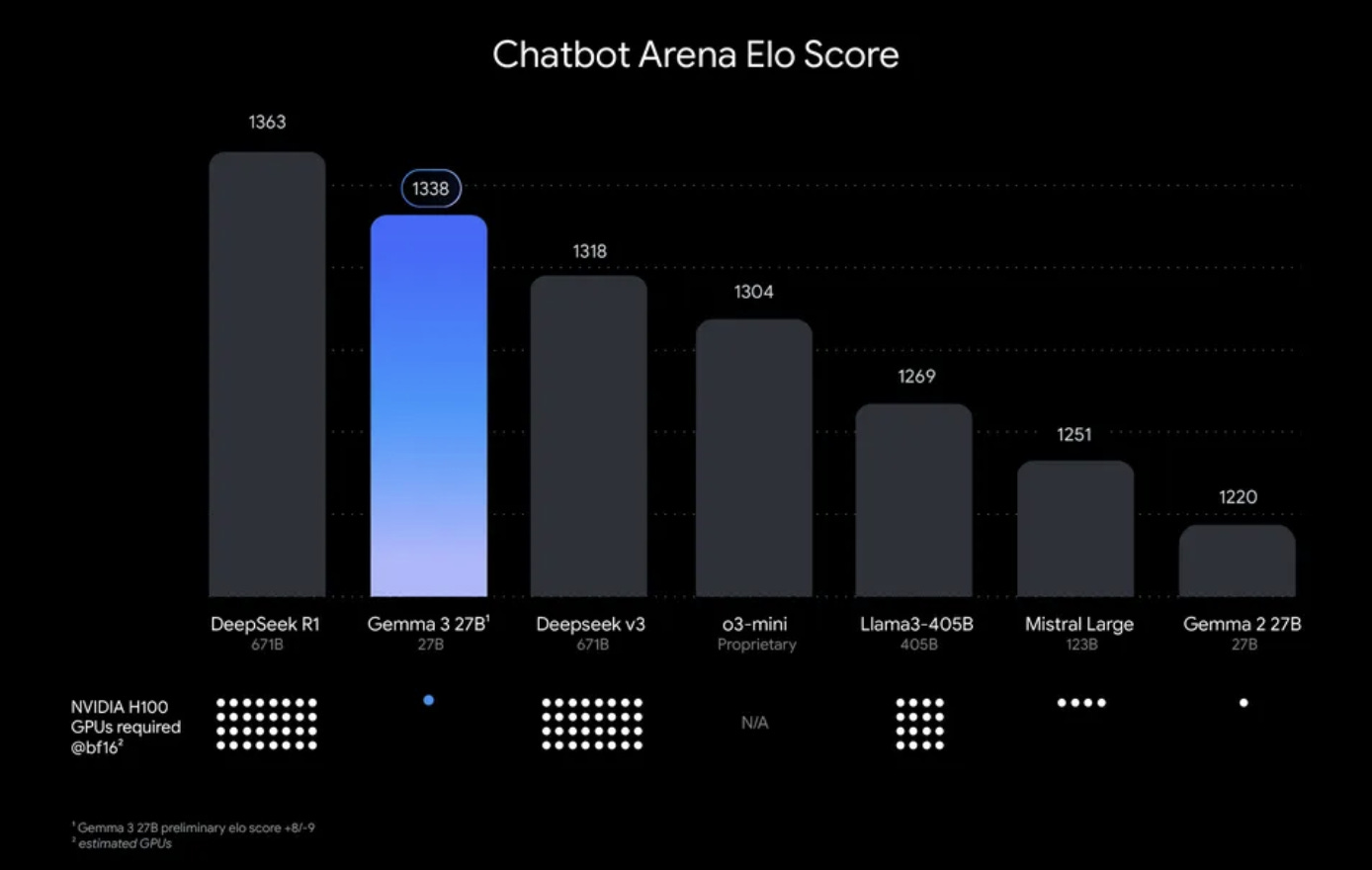
The model family comes in four sizes (1B, 4B, 12B, and 27B parameters). The 27B model ranks second on LMArena, just behind DeepSeek-R1, outperforming larger models like Llama-405B, DeepSeek-V3, and o3-mini, making it one of the strongest open models that can be run on a single GPU.
As reported in a previous newsletter, we did try out the Gemma family models, even though there are still some inaccuracies here and there, these models hit a sweet spot of being open-source, multimodal, small and fast enough to be deployed across devices.
Despite having the first-mover advantage when launching ChatGPT more than 2 years ago, it feels like OpenAI is falling behind and others are catching fast.
This is because Deep learning just worked. The formula for success was clear: feed a massive dataset into a huge neural network and train it for a long time. Just follow that and then the magic happens.
With all other strong players like Anthropic or Deepseek on the race, is Google going to win the AI Race with the launch of Gemini 2.5 Pro? And we are not just talking about pure performance. Compared to reasoning models, Google is giving away free access through AI Studio and API with just a few clicks.
Remember the time when Google first launched Bard, some declared Google the AI winner prematurely. While Google didn’t “win” back then, they always had the essential ingredients to become the winner: the tech, talent, funding, infrastructure, and ambition and prestige. Now, it seems they are fully leveraging those assets.
The AI race just got a lot more interesting.
What we’ve been reading/watching this week
- Can AI help us communicate with dolphins?
- Scientists recreated the visual cortex of a mouse’s brain
- OpenAI said it would release its first open model, a language model with open weights in coming months.
- Newer thinking models like o3 are become better at lying and increasingly stubborn when confronted with evidence
That’s it for now. Catch you soon!
With love,
Lan and Robert
