Textbook vs Reality: a closer look at vector embeddings
When the text book examples do not match reality.
Relying on vector embeddings may fail your RAG system.
If you’ve ever built a retrieval-augmented generation (RAG) system, you’ve probably come across cosine similarity. It is commonly used to compare relevance between two pieces of text (eg query and a document), which is at the heart of most retrieval systems. What’s interesting is that you often read that a cosine similarity of 1 means perfect semantic matching, while a score of -1 (angle 180 degree) indicates two texts that are completely unrelated (semantically). But then when you start building your retrieval system, something doesn’t add up. The best ranking documents do not have scores close to 1, and the worst ranked documents are never close to -1.
So I spent my evening generating tens of thousands cosine similarities (you can use other metrics like dot product, euclidean etc) between randomly selected text pairs and plotting the histograms and probability distributions (See figure).
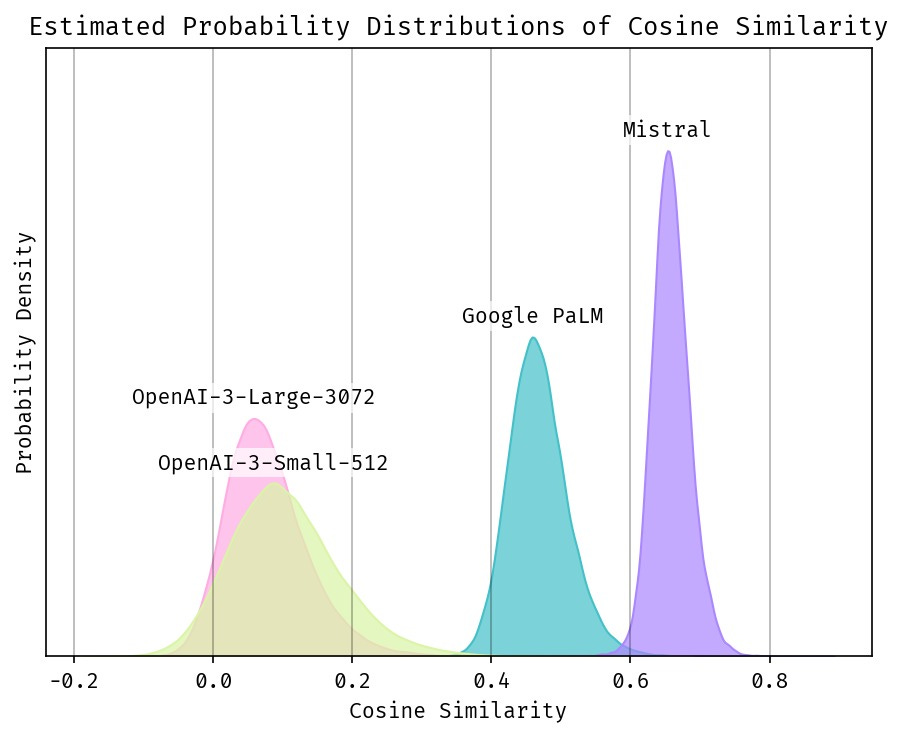
Mistral and Google PaLM show narrow similarity ranges, with most scores clustering tightly (e.g., Mistral between 0.6 to 0.8, PaLM at 0.4 to 0.6). OpenAI’s newer models - 3-large and 3-small exhibit broader ranges, with scores distributed more evenly from -0.2 to 0.4. This is closer to our intuition that “1” means very similar and “-1” not so similar.
Apart from the fact that the scores aren’t centered around 0.0, the distributions look very narrow, don’t they? It seems like a score of 0.99 would practically never happen. This is simply because there are so many more possible texts out there that are just not relevant. Imagine picking a random book at the library and trying to find another book that’s similar. You might find a handful, compared to thousands that are not relevant at all.
A similarity score of 0.4 could either mean completely unrelated or super relevant
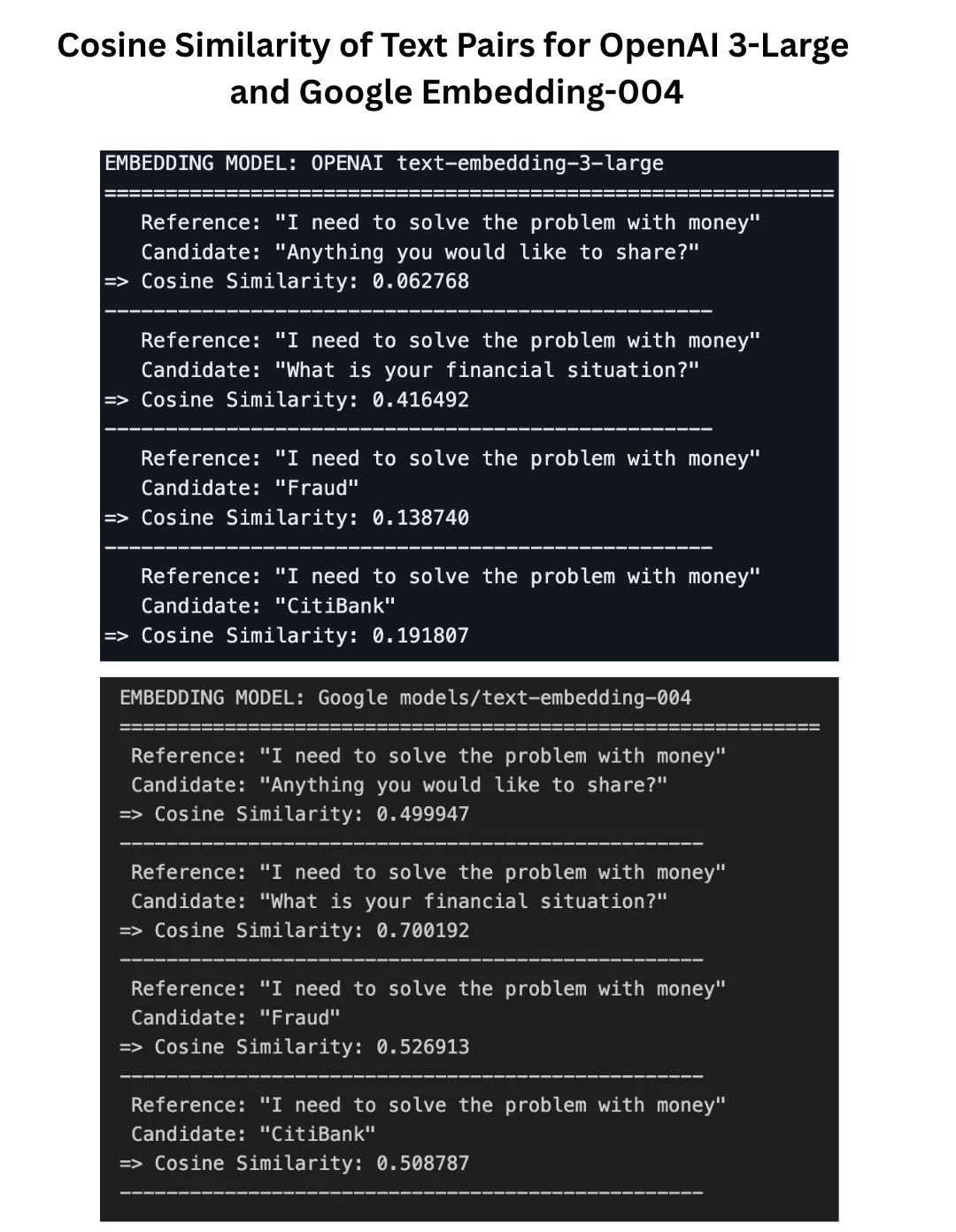
Let’s take a look at a few examples to get a better feel for how to interpret the cosine similarity score, by comparing an OpenAI embedding model with one from Google.
While the best matching score for OpenAI is around 0.4, the worst score from Google’s embedding model is around 0.5 (higher than openAI’s best score!)
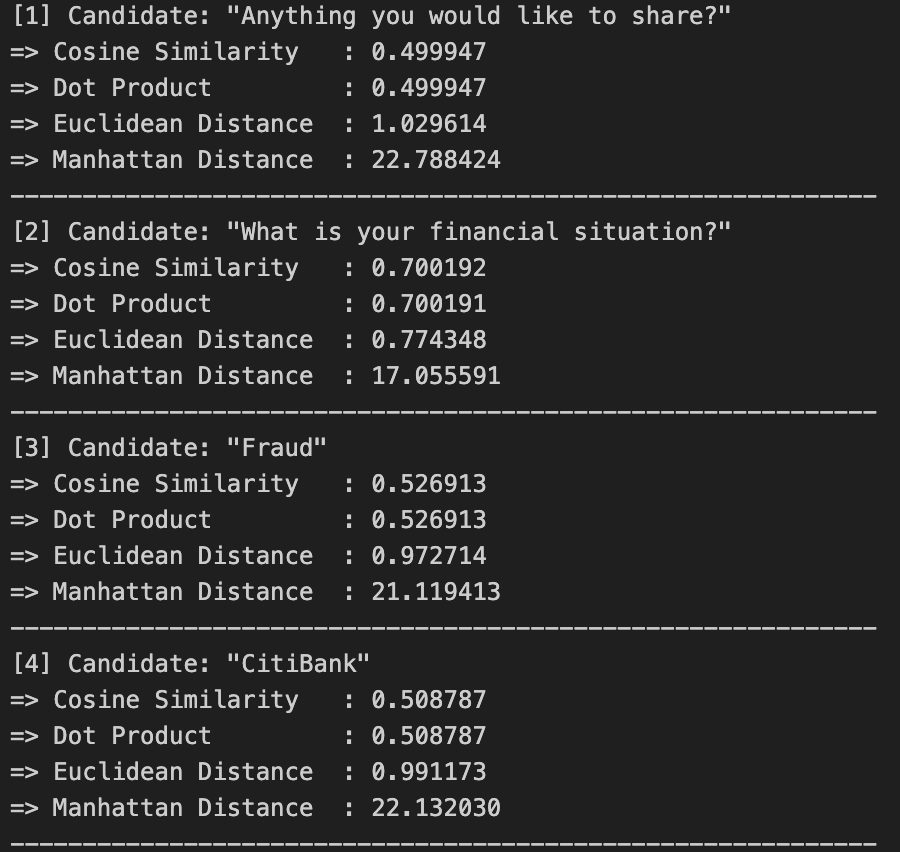
I also compare different similarities metrics in case you’re interested
So here’s the takeaway
Cosine similarity (or any other metric) alone doesn’t mean the same thing across models. Depending on the embedding model, a similarity score of 0.4 could either mean completely unrelated, or super relevant. You may end up retrieving too much or retrieving irrelevant things unless you understand these score distributions and tune your thresholds precisely.
Also, I have noticed that, with RAG’s popularity, it seems that often RAG is synonymous to building an index based on semantic search, or embeddings.
Let’s not forget, retrieval is not something RAG invented. Information retrieval has been around for a century. Back in the day, what did we do to retrieve relevant documents? Yep that is right, our good friend BM25. Simple, fast and effective. Term-based retrieval solutions like BM25 have successfully powered many search engines. Research like in “Old IR Methods Meet RAG” has shown that traditional term retrieval methods (e.g. BM25) outperformed semantic (dense) retrieval.
That said, term-based systems aren’t flawless either. Consider this lyric from Ed Sheeran’s Merry Christmas:
“Fill a glass and maybe come and sing with me.”
A keyword-based system might naively match this to eyewear instead of drinks, simply because of the word “glass.” In this case, semantic retrieval could definitely works as a refinement strategy.
So while vector embeddings have their place, especially in fuzzy matching or disambiguation, you might want to think twice before using them as your primary retrieval strategy.
If you want to dive deeper, here’s an insightful (though older) thread:
https://community.openai.com/t/some-questions-about-text-embedding-ada-002-s-embedding/35299/3
What we’ve been reading/watching this week
-
I am now (re)reading the old gem “How to win friends & influence people”. I became the AI tech lead earlier this year and with that new position, came something I didn’t expect: a lot more talking to people and you know, working with people has always been a bit of a struggle. Let’s not forget, for some (good) reasons, people never quite managed to agree with each others. All the conversations about resources, priorities, timelines … everyone’s got a different perspective, and sometimes it feels like we are all solving a different problem in the same room.
I first read this book in my early 20 and feel like it was just classic common sense advice but now in my early 30s, everything mentioned in the books just make perfect sense.I’ve seen my own behaviours — and my colleagues’ — reflected in those pages, and I’ve made so many notes.
If you haven’t checked it out, I highly recommend it. -
Microsoft created NLWeb, a tool that allows you to create a natural language interface for your website, essentially an MCP and allow AI interact and read your website contents more effectively. Is this the first step towards an internet that is traversed mostly by AI agents and not humans?
-
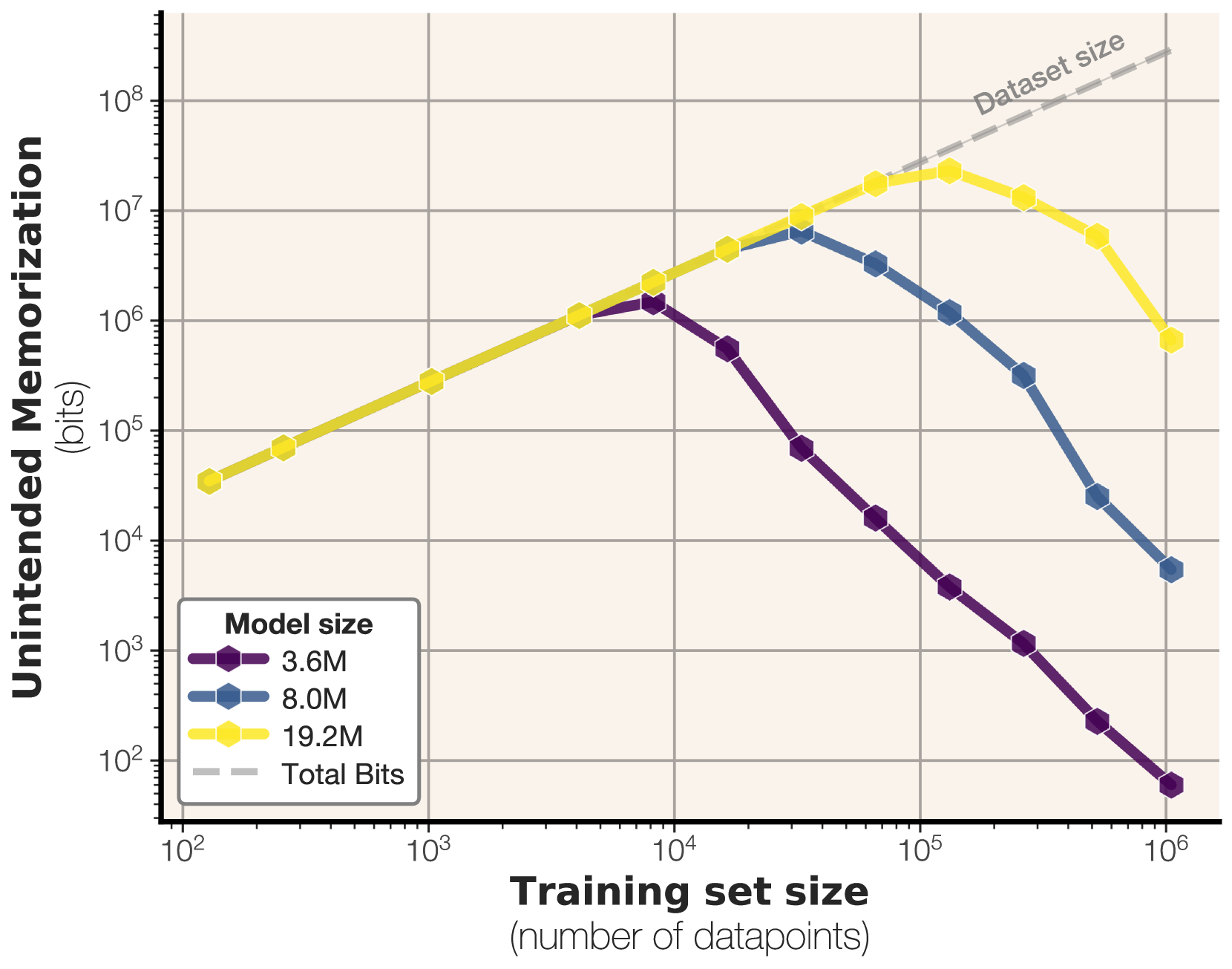
A new research paper on how large language models memorize information. The researchers find scaling laws that tell us how much information is memorized by an LLM before it starts to generalize. Surprisingly, all models that were trained followed similar patterns.
That’s it for now. Catch you soon!
With love,
Lan and Robert

Meet us on ai-stories.io