Tiny Models: the future of AI?

(Original image by Anna Kang’s You Are (Not) Small, adopted by me)
Last week, I was giving a talk at an Interbank event, and someone asked me: Should we care about Small Language Models (SLMs) when Large Language Models (LLMs) are dominating the headlines?
It’s a fair question — and I’ve seen many cases where smaller can beat bigger.
For example, a team I know was building their own embedding model for traction monitoring, and its performance on categorizing transactions is solid. At a recent data event, a speaker showed how Decathlon developed their own search/embedding model for their website — and it even outperformed mainstream search engines like Google search. This small embedding model saves the company a large amount of money from building a Google search engine for 80 countries on their website.
The good things about this SLM are control and security.
It is scary how much data we share with AI models. Not talking about that AI is trained on data that is scraped from the web, but simply what we share with it. Chatting with an AI every day to help you debug your code, suggest movies and books, help plan your next vacation, and more. By now, whichever chatbot you use knows more about you than Google and Facebook do based on your browsing history. And now that agentic AI is becoming more mainstream, this will only get worse.
We wrote last time that the adoption rate of AI is affected by how much we trust it. No one will enter their credit card details into an AI agent if there’s the risk that the AI will either buy the wrong items at the wrong price, or enter your details on a scam website, or that openAI has access to your details through the chat history. OpenAI, Anthropic and others spend a lot of time and money into safety of their models, but using SLM that are running directly on your device is another way of building trust.
This is not the only benefit, running locally also means that you can use the model without an internet connection and have almost no latency. For the big tech companies, there is the additional benefit that sending everything to the cloud doesn’t scale nicely e.g cost can increase significantly or there was an outage and the models are not reachable.
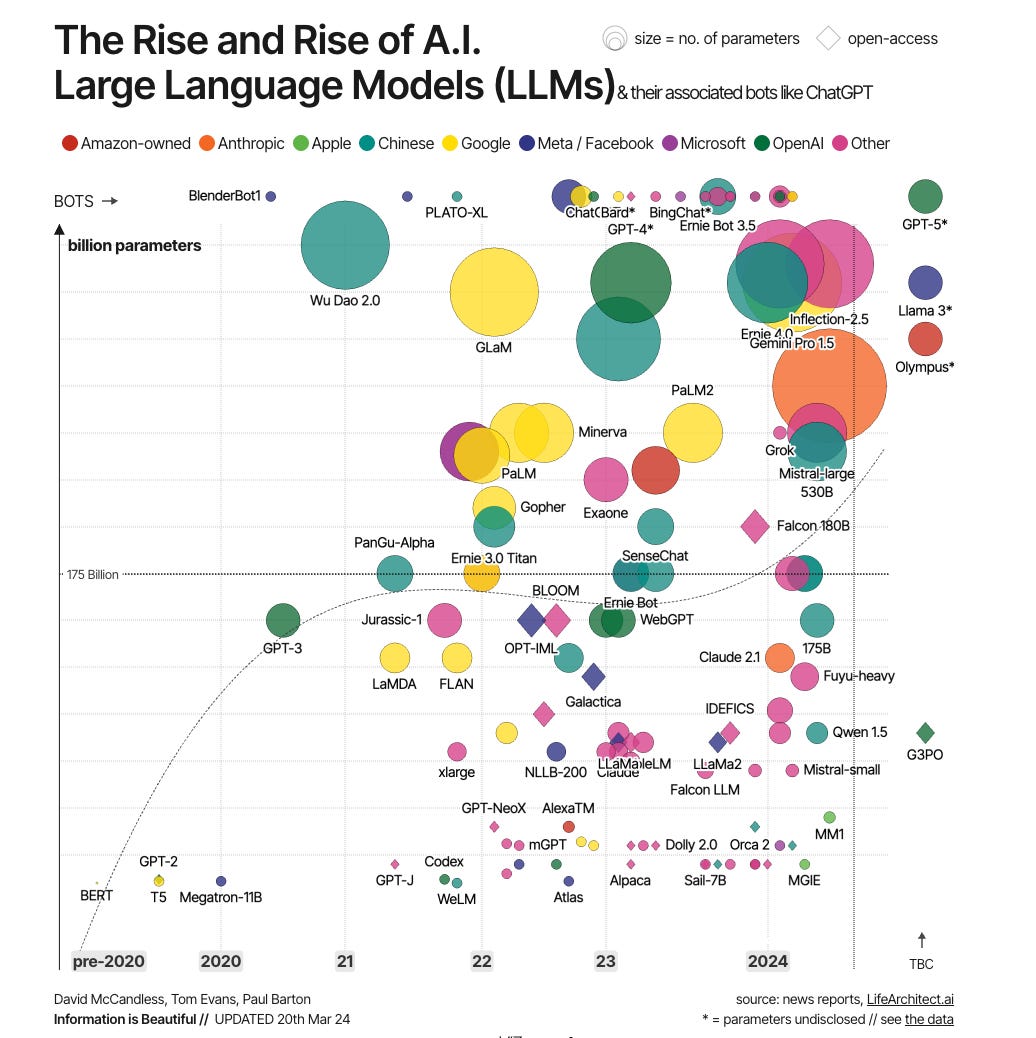
The SLM run with under 1 billion parameters, while still achieving surprisingly high performance. Meta’s Llama 3.2-1B and Microsoft’s Phi-3.5-Mini for example perform only a few percent worse on benchmarks compared to the flagship models while using only 1% of the computational power.
Besides us regular consumers that are concerned with privacy and safety, these small models are extremely valuable in fields like defense, healthcare, manufacturing and self-driving cars.
A friend of mine works on a project for the Dutch Ministry of Defense, where security is such a concern that their laptop is not even allowed to have access to the internet.
Most countries have very strict privacy laws concerning patient data, and analyzing data by sending patient data through an external API is a big no.
Similarly, in manufacturing, when data security is important or when an assembly line is in a remote location, connecting to an external API is not possible.
Lastly, imagine that self-driving cars would have to wait for a cloud response before deciding whether to break for a pedestrian crossing the street or not.
In these four examples, locals models provide a valuable solution. It helps the developer with code suggestions, is completely secure, ensures compliance with privacy laws and reduces latency for read time analysis and diagnosis.
All of this is possible thanks to four key techniques:
- knowledge distillation: where large “teacher” models train smaller “student” models
- strategic pruning: removing redundant neural pathways
- precision quantization: reducing numerical precision without meaningful accuracy loss
- specialized chips: NVIDIA’s Jetson series delivers 275 TOPS of AI performance, Qualcomm builds AI processing directly into mobile chips, and TSMC produced a G5 chip for the next generation Google mobile devices.
A Tale of Two Paths
When new technology arrives, the natural instinct is to chase it. Companies rush to adopt AI and want to try it out to see what is possible and what is not. Of course, there is a reason why LLMs dominate the headlines: convenience. With a ready-to-call API, you don’t need a team of engineers and data scientists to fine-tune and train a model. You don’t need production servers to host it. And you don’t need to keep maintaining it as your data drifts over time. That does explain the headlines of LLM.
And while the headlines go to giant models, the wave of SLM is happening in silence too, and they are multiplying even faster.
A couple of months ago, Google released Gemma 3, a family of lightweight multimodal models delivering performance comparable to larger models while running on a single GPU or TPU. These models hit a sweet spot of being open-source, multimodal, secure, small, and fast enough to be deployed across devices. And it’s not just the models that are getting smaller while maintaining performance, the technology is moving fast as well. Last week Google announced that their new phones will host a new chip called the G5, which is 60% faster than the previous generation G4 and is optimized for AI related tasks.
The future of AI might be more than a single story of “bigger is better.”