Why AI hallucinates (And Why it’s our Fault)
I can’t think of a life without using AI assistants, and while they are generally very helpful, they unfortunately either make confident mistakes (hallucinations), or incorrectly claim it doesn’t know something (over-refusal). Two research papers appeared this week that claim that both these issues stem from the same problem: we accidentally taught our AI to be “good test takers” rather than honest assistants.
A recent research by OpenAI shows that hallucination is an accidental feature that is introduced during pre-training and post-training.
Hallucinations as an outcome of pre-training
During pre-training, the model is rewarded for producing token sequences that actually occurred in the corpus. There is no explicit supervision that says “this whole sentence is factually correct,” only that the sequence fits the statistical distribution of the training text. These generative errors arise naturally during pre-training, just like misclassification errors in supervised learning, because pre-training minimizes cross-entropy over token continuation.
One surprising result from OpenAI’s research on their models is that the pre-trained models are more calibrated about their knowledge than the post-trained models.
This means post-training makes the models worse at knowing what they don’t know.
Post-training reinforces hallucinations
During post-training, which could be fine-tuning or reinforcement learning, we perform different tasks to make the model more performant on specific tasks like coding and reasoning, or more aligned with human values.
But hallucination further persists because of the way we evaluate the language models during post-training. The majority of evaluation benchmarks rely on binary grading systems—metrics like accuracy or pass rate—that treat every answer as simply right or wrong.
This setup creates a false dichotomy. It gives no credit (and often even penalizes) expressions of uncertainty, while rewarding plausible guesses. When saying “I don’t know” gets you a penalty but a plausible guess might earn full credit, the optimal strategy is clear: guess.
In other words, we trained them to be “good test takers” where guessing is rewarded over honest uncertainty. When faced with insufficient knowledge (internal and external), many models have learned that it is better to guess than to say “I don’t know”.
Optimizing models for these benchmarks may therefore reinforce hallucinations. Just like some human exams that already penalize blind guessing, OpenAI proposed to stop rewarding models for their confident guessing. Instead, make models say how confident they are and only provide an answer when their confidence passes a certain threshold, since mistakes at high confidence are heavily penalized.
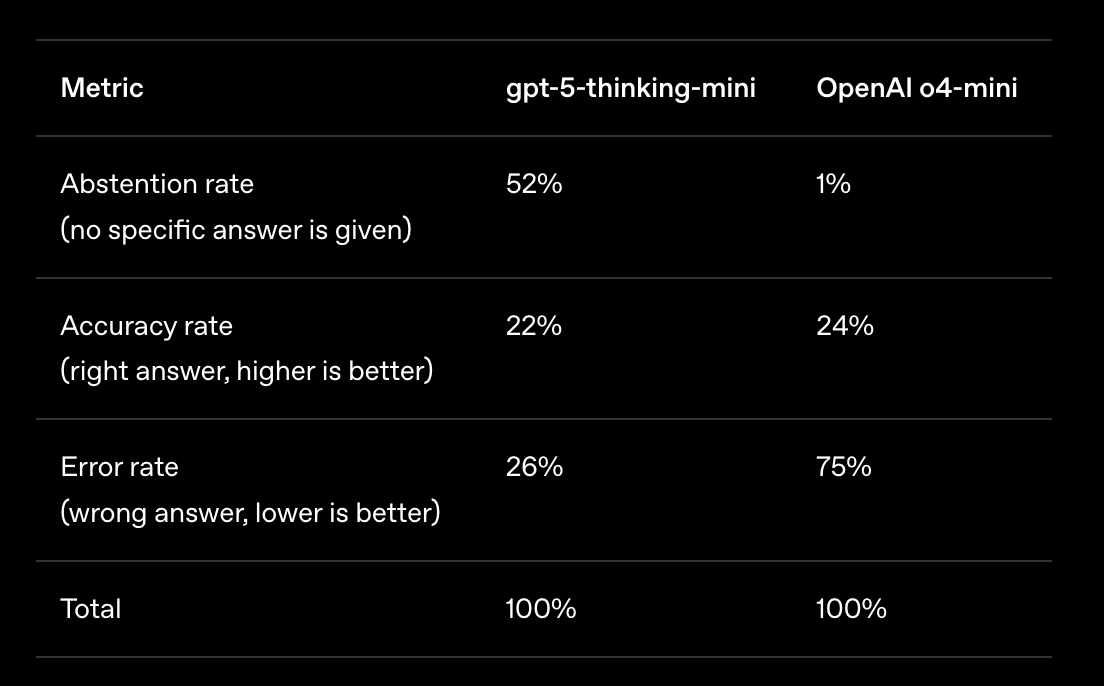
GPT-5-thinking model leveraged this confidence-targeting strategy, abstaining when it lacked sufficient certainty, resulting in a significantly lower error rate (e.g. hallucination rate) as compared to 4o-mini: 52% versus 1%. Strategically guessing when uncertain improves accuracy but increases errors and hallucinations.
When Extra Knowledge Backfires: Over-Refusal in RAG
While the confidence-target strategy addresses one pain point during training, there is an additional challenge. RAG is often introduced as a solution to hallucination since giving the model extra context should, in theory, reduce the need to bluff.
However, a recent paper has shown that when confronted with search results that are not relevant, models can still refuse to answer even when they possess the relevant internal knowledge. This over-refusal leads to systems that are either overconfident in some contexts, while being too hesitant in other contexts.
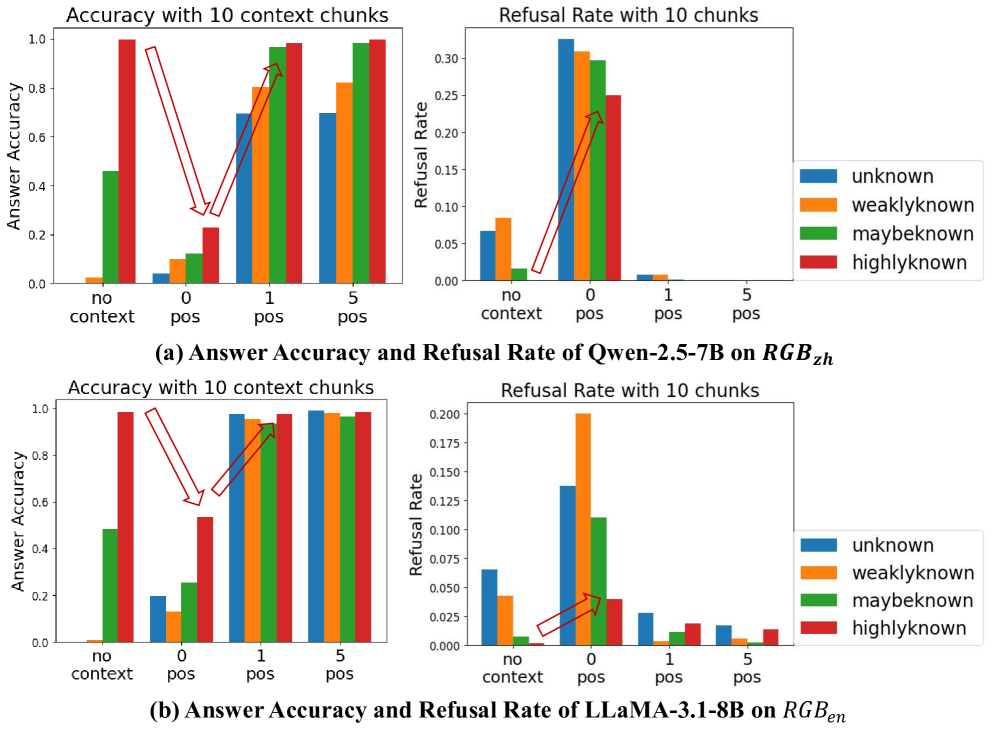
From the graph above, we can see that, when no context is retrieved there is a large increase in the refusal rate even for questions that the model internally knows.
The root cause is the same as the OpenAI researchers claim: binary evaluation metrics. Their solution, however, is slightly different.
The researchers tried two techniques: R-tuning and in-context fine-tuning. Training the model on how to refuse answers (R-tuning), made the problem worse. The AI became so cautious about using the provided context that it struggled to answer correctly even when given good information, effectively harming its own self-awareness. In-context fine-tuning, however, where “I don’t know” is inserted in training examples, did positively improve RAG models.
Conclusion
Hallucination is a predictable outcome of pre-training and post-training, and evaluation.
We will most likely never erase hallucinations completely. RAG has shown that even adding external knowledge is not enough — without proper calibration, over-refusal or overconfidence can persist. But we can change the incentives: shift evaluations away from binary grading, reward calibrated confidence, and normalize “I don’t know” as a valid outcome. Doing so won’t make models perfect, but it will make them less likely to “bluff”.