Why Your RAG System Might Be Failing (And It's Not Your Fault)
With RAG’s popularity, it seems that often RAG is synonymous to building an index based on semantic search, aka embeddings.
Despite the excitement around semantic search and vector databases, we’re seeing cases where performance is surprisingly and embarrassingly poor (see e.g. the paper Old IR Methods Meet RAG).
The Google DeepMind Reality Check
Recently, Google DeepMind did a thorough investigation on how well vector embedding models perform in retrieval tasks. The (not so) surprising result is that embedding models generally perform poorly. The reason for this is a theoretical limitation of the single-vector representation.
LLMs represent words, sentences, ideas and concepts all as simple sequence of numbers, which we refer to as the “embedding dimension”. When building a retrieval system there is a trade off to be made: smaller dimensions means smaller databases and faster retrieval. But, at a potential expense in retrieval accuracy and recall.
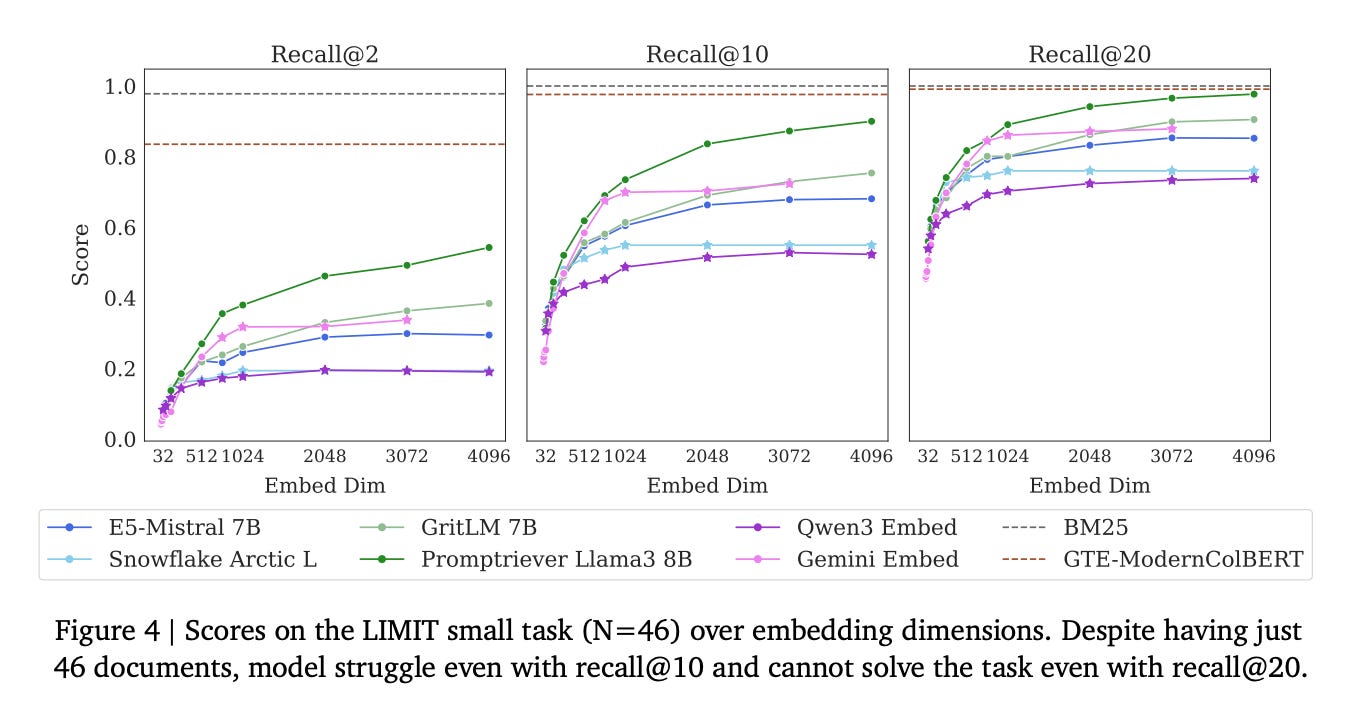
From Google DeepMind’s experiments however, even when they increased this dimension from 32 to 4096 performance was not good. This is true for every model they tried (Gemini, Llama, etc.). More importantly, the performance of every model plateaus as we increase the number of dimensions, supporting Google’s claim. In other words, even if we would increase the dimensions to 10.000, 100.000 or even more it would not help.
The good old BM25 wins
And the non-embedding models? Good old BM25 is the clear winner, with GTE-ModernColBERT a clear second place. BM25 achieve perfects recall even with recall@2.
Now, you may remember that retrieval is not something RAG invented. Information retrieval has been around for a century. Back in the day, what did we do to retrieve relevant documents? Yep that is right, our good friend BM25. Simple, fast and effective. Term-based retrieval solutions like BM25 have successfully powered many search engines.
But let’s be fair about the test
However, it is worth mentioning here that thing, is that the task is relatively simple. The dataset in the experiment consists of a collection of queries and documents and each query was run on a pool of 46 documents (2 relevant, 44 irrelevant). One of the example pair of query-document in the experiment as below:
query: “Who likes Quinoa?”
Document: “Olinda Posso likes Bagels, Hot Chocolate, Pumpkin Seeds, The Industrial Revolution, Cola Soda, Quinoa, Alfajores, Rats, Eggplants, The Gilded Age, Pavements Ants, Cribbage, Florists, Butchers, Eggnog, Armadillos, Scuba Diving, Bammy, the Texas Rangers, Grey Parrots, Urban Exploration, Wallets, Rainbows, Juggling, Green Peppercorns, Dryers, Pulled Pork, Holland Lops, Blueberries, The Sound of Wind in the Trees, Apple Juice, Markhors, Philosophy, Orchids, Risk, Alligators, Peonies, Birch Trees, Stand-up Comedy, Cod, Paneer, Environmental Engineering, Caramel Candies, Lotteries and Levels.”
In this case it is quite clear why embedding models perform poorly on this dataset. “Quinoa” simply has little semantic overlap with “a long list of things that include Quinoa”. Whereas with BM25 there are only two documents in the dataset that contains “Quinoa”.
Where Embeddings Actually Shine
Does this mean vector embeddings are useless? Not at all. They’re essential in many NLP tasks—especially when queries get long and nuanced.
Take the example above: if the dataset contained documents saying “Bob does not like Quinoa,” suddenly BM25 would plummet in performance. Why? Because BM25 would return documents containing the word “Quinoa” without knowing it should also return documents related to disliking. However, an embedding model is more likely to pick up this kind of nuance.
Or consider another example with the word “apple.” It could mean the fruit or the tech company. Now imagine the query:
“What’s the latest Apple product?”
A sparse method might just match the word apple and would return also the apple fruit. But a good embedding model understands that latest product implies technology—and ranks iPhone or Mac-related content higher.
The Smart Approach
That’s why embedding models are essential in many NLP tasks, especially when your queries get long and nuanced. Rather than relying solely on vector embeddings, use them as a refinement layer. Start with sparse search as your foundation to maximize recall and then use vector embeddings to get the relevant listings to the top.
The best retrieval isn’t about choosing sides—it’s about using the right tool for each part of the job.